ADP公開一周年記念記事がまだ途中ですが、
Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、
LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。
実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。
,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。
,$db = "DSN=Trade"
,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price"
,$company = "SELECT NAME FROM Company WHERE CODE = ?"
,sql( $db, $price, [], @rec)
,pipe
,sql( $db,$company, [$rec[0]], $name)
,csv($rec,$name).prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。
実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。
,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。
,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の
,sql@($db,$str,[]).
pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
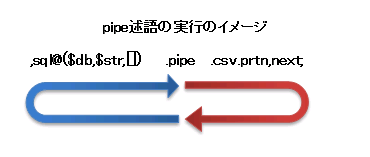
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。

比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。
,$db = "DSN=Trade"
,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price"
,$company = "SELECT NAME FROM Company WHERE CODE = ?"
,sql( $db, $price, [], @rec)
,pipe
,sql$( $db,$company, [$rec[0]], $name)
,csv($rec,$name).prtn,next;
実行時間は、約89秒で実験2と比べて約24%速くなっています。
興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。
,$db = "DSN=Trade"
,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price"
,$company = "SELECT NAME FROM Company WHERE CODE = ?"
,sql( $db, $price, [], @rec)
,pipe
,sql$( $db,$company, [$rec[0]], $name)
,pipe
,csv($rec,$name).prtn,next;
実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。
,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。
pipe述語の効果
| 実験 | 実行時間(秒) |
|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
以前に書いた
この記事に関してコメントをもらいちょうど記事にしようかと思っていたところでしたので、ADPのキャッシュ機能を使い、
この記事の実験をADPでやったらどうなるかみてみます。
SQLでjoin(結合)と言えばSQLに慣れた方にとっては馴染み深いものですが、初心者にとっては一種の登竜門のようで、joinを避けたコードを見かけたりすることがあります(まぁ私も十数年前にはこのような理由でjoinを避けたコードを書いた記憶があります)。また、O/Rマッパーではテーブル毎にクラスを対応させる関係で、joinの取扱がややこしかったりします。
それ以外でも、私の場合になりますが、過去にパフォーマンス上の理由からjoinを行わなかったことがあります。
今回は、前回の実験と同様に
・SQLでjoinさせる。
・ADPでjoinさせる。
でパフォーマンスの違いについていくつかの実験を行い計測します。
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。
実験1 素直にSQL側でjoinをさせたものを実行
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。
,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
少しコードの説明を、
1行目の、$db=~ の部分は、ODBCの接続文字列を指定します。上記のコードは、ODBCのデータソース名Tradeを指定している接続文字列になっています。
2,3行目の、$strの部分はSQL文を変数$strに代入しています。本来は1行で書けますが、wordpressで見やすいように2行で書いています。
4行目の
,sql@($db,$str,[]).csv.prtn,next;
sqlは組み込みの述語で、「ODBC-APIを使いsqlを実行し、結果を配列(@)で受け取り、csvに変換し、prtnで画面に出力し、nextで全ての結果を出力する」というコードになります。
自画自賛になりますが、必要最低限の情報だけで簡単にSQLが発行できているので、ADPの開発目標の一つである「SQLとの親和性が高い言語を目指す」を具現している例だと思います。
実行時間ですが、
D:\>adp -t sql_test_1.p > sql_test1.txt
time is 119192ms.
で、約119秒となりました。
実験2-A ADP側でjoin(ネステッドループ)
続いて、ADP側でネステッドループjoinさせてみましょう。
,$db = "DSN=Trade"
,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price"
,$company = "SELECT NAME FROM Company WHERE CODE = ?"
,sql( $db, $price, [], @rec)
,sql( $db,$company, [$rec[0]], $name)
,csv($rec,$name).prtn,next;
ADPのDBライブラリは、前に紹介しました
ODBCライブラリがベースになっていますので、ODBCのパラメータクエリが使えます。
5行目のコードがパラメータクエリを使っています。
実行時間ですが、
D:\>adp -t sql_test_2.p > sql_test2.txt
time is 1717284ms.
で、約1717秒となりました。実験1と比べて約14倍の実行時間です。
実験2-B ADP側でjoin(ネステッドループ&キャッシュ)
さらに続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。
,$db = "DSN=Trade"
,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price"
,$company = "SELECT NAME FROM Company WHERE CODE = ?"
,sql( $db, $price, [], @rec)
,sql$( $db,$company, [$rec[0]], $name)
,csv($rec,$name).prtn,next;
呼び出し述語名の後ろに$をつければキャッシュ機能がONになります。上記のコードでは5行目の sql$ がキャッシュ機能を使用しています。
では、実行時間をみてみましょう。
D:\>adp -t sql_test_2.p > sql_test2.txt
time is 116770ms.
で、約117秒となりました。
実験2-Aと比べるとかなり高速化がはかられたかと思います。キャッシュのこのような使い方は、かなり有効だとうことが解るかと思います。繰り返しになりますが、ADPならお手軽にキャッシュ機能を使うことができます。
実験3 ADP側でjoin(事前にマップ作成)
ちなみに、ADPでも事前にマップを作成し、joinを行うことができます。
以下、コード例です。
,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
前回の記事ではC++でハッシュjoinを行うと書いたので『ハッシュJOINを言語で再開発するのは非効率』とコメントをもらいました。
コードを良く読んで頂ければ解るかと思いますが、実はC++の例でもjoin自体はプログラミング言語(ライブラリ)の機能を使っており、取り立てて複雑なことはしていません。
やっていることを説明しますと、マスターテーブル用のマップを事前に作成し、それを使ってjoinを行っています。慣れていない人にとっては難しいかもしれませんが、古くはperlの連想記憶、最近(これも古いが)の例ではVBScriptのディクショナリに相当します。DBMSを使わないで日常的にファイル処理を行っている方にとっては日常的なコードかと思います。
ちなみに、ADPのコード例ですが非常にすっきりとしているかと思います。C++の例と比べると本来やろうとしていることが明確になっているかと思います。
実行時間は、
D:\>adp -t sql_test_3.p > test3.txt
time is 110988ms.
で、約111秒とやはり実験1より速くなっていることが解ります。
こうしてみると、実験2-Bが思いのほか速くなっていないと思わるでしょう。
これはSQLの実行回数に関係しています。
各実験のSQLの実行回数を見てみましょう。
SQLの実行回数
| 実験1 | 1回 |
| 実験2-A | 約470万回(Priceテーブルの行数+1) |
| 実験2-B | 約2000回(Companyテーブルの行数+1) |
| 実験3 | 2回 |
になります。実験2のコードではテーブルの行数に比例した数だけSQLを実行することになります。実験2-Bが実験2-Aより速いのは、Priceテーブルの行数よりComapnyテーブルの行数が圧倒的に少ないから、つまり1対nの結合を行っているからで、仮に1対1の結合では速くならないということになります。
実験3がなぜ実験1より速いかですが、DBMS側から転送されるデータ量が違います。
以下、CSVファイルの先頭5行を表示します。
1717,2005-05-10 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
1717,2005-05-11 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
1717,2005-05-12 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
1717,2005-05-13 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
1717,2005-05-16 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
企業名の『明豊ファシリティワークス(株)』が重複して余分なデータとなっています。実験1のコードではDBMSから言語側にこのように重複したデータが来ます。各実験で転送されるデータ量を見てみましょう。
結果データの転送量(CSVファイルベース)
| 実験1 | 約256MB |
| 実験2-A | 約256MB |
| 実験2-B | 約184MB |
| 実験3 | 約184MB |
実は、DBMSから言語側へ転送されるデータ量自体は、実験1より実験2-Bの方が少なくなります。そのような関係で、実験1より実験2の方が早くなっています。SQLの実行回数(実験1の方がよい)とデータ転送量(実験2の方がよい)になりますが、このあたりはハードウェアの環境やDBMSによって結果が変わってくるでしょう。
この2つのデータから実験3は、なるべく少ないSQLの実行回数で少ないデータ量を転送しているということが解るかと思います。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
@IT エンジニアライフのコメンテータ(だった)生島さんのコラム
http://el.jibun.atmarkit.co.jp/g1sys/2010/05/post-2d1b.htmlのコメント欄に参加しました。
生島さんのコラムですが、過去に度々炎上してきましたが、炎上するたびに、
『SQLはオブジェクト指向言語の数十倍の効率』
という、この手の話が出てきます。この手の呪文は他にも幾つかあるのですが、これを出せば議論が終結するというある種の必殺技みたいに使われます。
が、それどころか、毎回、毎回、明確な結論が出ずにさらにコメント欄が荒れます。
私としては、本来はどうでもよい話なのですが、いきがかり上、私も思わず、
「私は、過去にSQLが遅いのでSQLを崩して、C言語でJOINをやらせて高速化しました。OO言語ではないですが、今だったらC++を使うでしょう(なぜってハッシュクラス があるから)。」
と発言しました。恐らく、多くの方は、
『いやいや、いくらなんでも、それはウソでしょう。』
とか、
『売り言葉に買い言葉でしょうが、それは良くないでしょう。』
とか、
『幾らC++が好きって言ったって、原理的にDBMS内で処理が閉じるSQLの方が速いでしょう。』
とか思われたことでしょう。
私も、そういうツッコミが来ることは重々承知していたのですが、現実に私は10年以上前になりますが、上記のような最適化を行ったことがありました。
以来、別にわざわざSQLを崩してCでJOINなんて事はしませんでしたが、逆にその後、さまざまなプロジェクトを通して、DBMSの動作をみる限り上記の最終手段は、まだ有効だなというのも実感としてあったのですが、あまりの共感の得られ無さにものすごい孤独感に襲われ、また生島さんの煽りも受け、このあたりで白黒はっきり付けたいと思います。
では、どのように白黒つけるのかですが、やはりベンチマークテストを行ってみるしかないかと思います。
つまり、生島さんが件のコラムのコメント欄に書かれた
TABLE_A a
INNER JOIN TABLE_B b
a.KEY = b.KEY
をもとにしたSQLをC++で書き実際に実行させてその実行時間をみてみましょう。
■実験の環境
<追記>この記事のコメント欄の指摘(サーバーとクライアントマシンが分かれていない)および環境が変わったので再現できない関係で、新しく環境を構築してテストをやり直しました。
今回実験したテスト環境を示します。
■実験するSQLとプログラムの概要
以下のSQLを実行させ、カンマをセパレーターとして標準出力へ出力させます。
CSVファイルへの出力を想定したSQL、JOINの部分は生島さんがコメント欄で指摘したSQLそのものになっています。このSQLをもとにJOIN部分をC++でやらせてみます。
SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME
FROM Price INNER JOIN Company ON (Price.CODE = Company.CODE)
■実験1 素直にSQL側でJOINをさせたものを実行
以下のコードのとおり、実験するSQLをそのまま実行してみました。
#include <iostream>
#include <time.h>
#include "../kz_odbc.h"
using namespace std;
int main(void)
{
kz_odbc db("DSN=Trade",true);
kz_stmt stmt(&db);
time_t t = time(NULL);
// テーブルからデータの取得
stmt, "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME "
" FROM Price INNER JOIN Company ON (Price.CODE=Company.CODE)"
, endsql;
kz_string_array result = stmt.next();
int cnt = 0;
while ( !result.empty() ) {
cout << result[0] << "," << result[1] << ","
<< result[2] << "," << result[3] << ","
<< result[4] << "\n";
result = stmt.next();
cnt++;
}
cerr << "Execute time is " << time(0) - t << "sec." << endl;
cerr << "Record count is " << cnt << "." << endl;
return 0;
}
コードですが、Wordpressに合わせて編集してますので、変なところで改行が入っていますが御勘弁を。
若干ですが、コードの説明を、
stmt, "SELECT ・・・・
とか
result.empty()
stmt.next()
の部分が私が作成した
ライブラリになります。といってもODBC APIを呼び出しているだけになります。そう特異なものでもないかと思います。
実行結果ですが、
Execute time is 131sec.
Record count is 4671568.
となりました。プログラムは標準出力に出力していますが、実行に際しては標準出力をファイルにリダイレクトしています。その方が実行速度は速くなります。
比較元のデータが無いので何とも言えませんが、1秒間に約3万5千件のデータがCSVファイルへ落とされているのでマシンスペックを考えますとまずまずでしょう。
ちなみに、実行ブランを確認しましたが、CompanyテーブルへのアクセスのTYPEはeq_refでユニークキーによるJOIN(最速のテーブルアクセス)が実行されていることを確認しました。
■実験2 C++側でネステッドループでJOINさせてみる
ループループといっていたものですが、いわゆるネステッドスープのことだと推測します。
#include <iostream>
#include <time.h>
#include "../kz_odbc.h"
using namespace std;
int main(void)
{
kz_odbc db("DSN=Trade",true);
kz_stmt stmt(&db);
time_t t = time(NULL);
// テーブルからデータの取得
stmt, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price", endsql;
kz_string_array result = stmt.next();
int cnt = 0;
while ( !result.empty() ) {
// JOINの実行(ネステッドループ)
kz_stmt stmt2(&db);
stmt2, "SELECT NAME FROM Company WHERE CODE = ? "
, result[0].c_str(), endsql;
kz_string_array result2 = stmt2.next();
cout << result[0] << "," << result[1] << ","
<< result[2] << "," << result[3] << ","
<< result2[0] << "\n";
result = stmt.next();
cnt++;
}
cerr << "Execute time is " << time(0) - t << "sec." << endl;
cerr << "Record count is " << cnt << "." << endl;
return 0;
}
実行結果は以下のとおりです。
Execute time is 1714sec.
Record count is 4671568.
これはものすごく遅いですね。生島さんが、
『SQLにすると数十倍速くなる』
といっていたのは、実験1のコードと実験2のコードを比べて言っていたと思われます。
では、これ以上に速くさせる方法はないのでしょうか?
生島さんの言うとおり、OO言語はSQLと比べて何十倍も遅いのでしょうか?
■実験3 C++側でハッシュJOINさせてみる
件のコメント欄で生島さんが難しいとおっしゃっていた、ハッシュJOINですが、実は特段、難しいものではありません。
以下のようにすっきりと実装できます。
ちなみにコード中に出てきますmapというのはバイナリサーチを行います。なので、正確にはハッシュJOINではありません。
C++でハッシュ検索を行うには、Boost等のライブラリを使う必要があります。
つまり今回のコードはある意味、最適化の余地を残しているのですが、ここではテストの再現性(環境設定)の手間を考えてmapを使います。
#include <iostream>
#include <time.h>
#include "../kz_odbc.h"
using namespace std;
int main(void)
{
kz_odbc db("DSN=Trade",true);
kz_stmt stmt(&db);
time_t t = time(NULL);
// マスターの取得・マップの作成
map< string, string> company;
stmt, "SELECT CODE, NAME FROM Company ", endsql;
kz_string_array result = stmt.next();
while ( !result.empty() ) {
company.insert( pair< string, string>( result[0], result[1]) );
result = stmt.next();
}
// テーブルからデータの取得
stmt, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price ", endsql;
result = stmt.next();
int cnt = 0;
while ( !result.empty() ) {
cout << result[0] << "," << result[1] << ","
<< result[2] << "," << result[3] << ","
<< company[ result[0] ] << "\n";
result = stmt.next();
cnt++;
}
cerr << "Execute time is " << time(0) - t << "sec." << endl;
cerr << "Record count is " << cnt << "." << endl;
return 0;
}
結果ですが、以下のとおり、実験1のコードよりも早くなっております。
Execute time is 108sec.
Record count is 4671568.
■結果
実行結果を再度以下に掲載します。
| 実験1(SQL) | 131秒 |
| 実験2(C++側でネステッドループ) | 1714秒 |
| 実験3(C++側でハッシュ) | 108秒 |
明確に結果が出ているかと思います。こんなに単純なテストの結果からでも
「SQLをばらしてJOINをC++で行えば速くなる場合がある」
ということは理解していただけれるかと思います。
また、
『SQLはオブジェクト指向言語の数十倍の効率』
というのは、単純に
「OO言語側の最適化が不十分である可能性がある」
ということも言えるでしょう。
ただ、実験3では、高々十数%しか速くなっていません。
ということであれば、通常はやはり実験1のようなコードの方がトータル(開発効率と実行効率を考えると)としては良いと思われる。実験3のような事実はあくまでも知識としてしておきたいところです。
追記、コメント欄の議論を踏まえて再度記事をアップしました。
追記、コメント欄の指摘(ローカルマシンで動かしている)を受けまして再度環境を作成して実験しました。
追記、まとめ記事を作成しました。
C++でDBへアクセスするにはMFCだの、ADOだのややこしいライブラリをリンクするか、黙ってCで記述(各DBのライブラリを直接呼び出すコードを記述)するか、マネージドコードの仲間入りになるかになる。
最近流行りの言語(PHPとか)はあっさりDBをサポートしているのにC++/STLでさくっとSQLを書きたい場合、結構骨が折れる。
と言う訳で、なんちゃってodbcクラスを作りました。
以下のようにSQLが発行できちゃいます。
db, "INSERT INTO test( c1, c2) VALUES(?,?)", "test", 100, endsql;
ぱっと見、何がなんだか分からないかもしれませんが、キモはSQL文に続けてパラメータが記述できる点で、結構楽にSQLが発行できます。
(見る人が見れば凶悪な演算子のオーバーロードに見えるかもしれないが・・・)
ちなみに、様々なDBに対応する為と、Linuxへの移植性を考えてODBCにしました。
ダウンロード(2011/04/15 SourceForgeにプロジェクトを作成しました)
Previous Page | Next Page