OpenBlockS 600
Windows7,2008R2に引き続き、これまた1年越しの作業になりましたが、我がohfuji.nameをホストするマシンをOpenBlockS 600(正確にはOpenBlockS 600D相当)に置き換えました。OpenBlockS 600とは、ぷらっとホーム社さんが製造・販売しているマイクロサーバーで、こちらが製品情報になります。ちなみに2月現在キャンペーンをやっておられます。
OpenBlockS 600自体の解説はいろいろな場所で行われているので、そちらにおまかせしますが、特質すべきは、抜群の低消費電力で、私がエコワットで測定した結果は9Wでした。またファンレスでストレージはコンパクトフラッシュを使うので音が出なくてかつ障害に強く、商業利用はもちろん、自宅サーバーとしても重宝するかと思います。
OSですが、OpenBlockS 600はSSD Linuxがプリインストールされています。また600DはDebianがプリインストールされています。メモリは1GB積んでいますのでDNSサーバーやメールサーバーとしては申し分ないスペックです。
難点が、CPUにPOWER-PCを使用しているところで、私のようなプログラミングをする人間にとっては開発環境を別途用意しないといけないのと、さらにそのCPUの動作周波数が600MHzとお世辞にも速いと言えないところで、Apacheで静的なページを運用するならともかく動的なページは難があるかと思います。特に普通のサーバーでも重たいWordpressをOpenBlockS 600で運用するのは厳しいかと思います。
では、このブログ(Wordpressなんですが・・)はどうしているのかと言いますと、このページはADPで作成したブログビューアーで表示しています。我がADPもOpen BlockS 600Dに移植しまして、このとおり動作しておる次第です。このページを頻繁に訪問される方は気がついておられたかと思いますが、最近Wordpressが重くなっていたので、どげんかせんといかんと思っておったところです。このような厳しい条件を克服するのはソフトウェアエンジニアとしてロマンを感じたりします。
しばらく運用してみてOKであれば、OpenBlockS 600D版のADPと共にブログビューアー(Adp WorPdress bLOG viewer - AWPLOG)のソースを公開しようかと思っております。
2011/06/23 追記:節電の為、自宅サーバー類は仮想マシンとして別のサーバーに集約しましたので、現在このサーバーはOpenBlocks 600D上では動作していません。
2011-02-07 | コメント:0件
自作機向けWindows7のKernel-Power 41病対策
Kernel-Power 41病というのは、Windows 7に特有の現象で、突然PCが再起動しイベントビューアにID:41の『システムは正常にシャットダウンする前に再起動しました。』というログがはかれる現象を指します。私はWindows7を使いだしてから1年になるのですが、それまではKernel-Power 41病というのがあるとは知らなかった(つまりブルースクリーンやら突然のリセットを見ていなかった)。
社内のPCをWindows7に入れ替えた後、社長のPC(自作機)が、たまに(2,3日に一度)リセットがかかり、いろいろ調べた結果、結構有名であることを知る。
一応マイクロソフト社さんのWEBページでサポート情報が上がっています。
社長のPCは、当初、シナリオ1でグラフィックドライバの不具合のような振る舞いをみせましたが、グラフィックカードを換えると、今度はシナリオ3の現象が発生しました。
ネットを検索しますと省電力機能の不具合により電力不足が発生することが原因らしいとのことで、それならと電源を換えて、メモリとグラフィックカードの端子を接点復活剤を使って掃除したところ、それから1週間経ちますが Kernel-Power41は発生しなくなりました。
電源を安物から少し良いものに換えたのでこれがあやしいのですが、ただ、現在その電源は私が使っているPC(これも自作)で使用していますがKernel-Power41は発生していませんので、接点復活剤の可能性もあります。今まで接点復活剤は気休めに使っていてあまり効果を実感したことがないのですが、今回は役にたったかもしれません。
巷では、省電力設定を無効にする(プロセッサの電源管理、最小のプロセッサの状態を100%にする。USBの省電力設定を無効にするとか)が有効らしいですが、それでもダメな方や省電力設定を切りたくないかたは、成功したらラッキー程度にご参考にして頂ければと思います(もちろん自己責任で)。
2011-02-02 | コメント:0件
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
以前に書いたこの記事に関してコメントをもらいちょうど記事にしようかと思っていたところでしたので、ADPのキャッシュ機能を使い、この記事の実験をADPでやったらどうなるかみてみます。
SQLでjoin(結合)と言えばSQLに慣れた方にとっては馴染み深いものですが、初心者にとっては一種の登竜門のようで、joinを避けたコードを見かけたりすることがあります(まぁ私も十数年前にはこのような理由でjoinを避けたコードを書いた記憶があります)。また、O/Rマッパーではテーブル毎にクラスを対応させる関係で、joinの取扱がややこしかったりします。
それ以外でも、私の場合になりますが、過去にパフォーマンス上の理由からjoinを行わなかったことがあります。
今回は、前回の実験と同様に
・SQLでjoinさせる。
・ADPでjoinさせる。
でパフォーマンスの違いについていくつかの実験を行い計測します。
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
少しコードの説明を、
1行目の、$db=~ の部分は、ODBCの接続文字列を指定します。上記のコードは、ODBCのデータソース名Tradeを指定している接続文字列になっています。
2,3行目の、$strの部分はSQL文を変数$strに代入しています。本来は1行で書けますが、wordpressで見やすいように2行で書いています。
4行目の
,sql@($db,$str,[]).csv.prtn,next;
sqlは組み込みの述語で、「ODBC-APIを使いsqlを実行し、結果を配列(@)で受け取り、csvに変換し、prtnで画面に出力し、nextで全ての結果を出力する」というコードになります。
自画自賛になりますが、必要最低限の情報だけで簡単にSQLが発行できているので、ADPの開発目標の一つである「SQLとの親和性が高い言語を目指す」を具現している例だと思います。
実行時間ですが、
D:\>adp -t sql_test_1.p > sql_test1.txt time is 119192ms.
で、約119秒となりました。
実験2-A ADP側でjoin(ネステッドループ)
続いて、ADP側でネステッドループjoinさせてみましょう。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
ADPのDBライブラリは、前に紹介しましたODBCライブラリがベースになっていますので、ODBCのパラメータクエリが使えます。
5行目のコードがパラメータクエリを使っています。
実行時間ですが、
D:\>adp -t sql_test_2.p > sql_test2.txt time is 1717284ms.
で、約1717秒となりました。実験1と比べて約14倍の実行時間です。
実験2-B ADP側でjoin(ネステッドループ&キャッシュ)
さらに続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
呼び出し述語名の後ろに$をつければキャッシュ機能がONになります。上記のコードでは5行目の sql$ がキャッシュ機能を使用しています。
では、実行時間をみてみましょう。
D:\>adp -t sql_test_2.p > sql_test2.txt time is 116770ms.
で、約117秒となりました。
実験2-Aと比べるとかなり高速化がはかられたかと思います。キャッシュのこのような使い方は、かなり有効だとうことが解るかと思います。繰り返しになりますが、ADPならお手軽にキャッシュ機能を使うことができます。
実験3 ADP側でjoin(事前にマップ作成)
ちなみに、ADPでも事前にマップを作成し、joinを行うことができます。以下、コード例です。
,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
前回の記事ではC++でハッシュjoinを行うと書いたので『ハッシュJOINを言語で再開発するのは非効率』とコメントをもらいました。
コードを良く読んで頂ければ解るかと思いますが、実はC++の例でもjoin自体はプログラミング言語(ライブラリ)の機能を使っており、取り立てて複雑なことはしていません。
やっていることを説明しますと、マスターテーブル用のマップを事前に作成し、それを使ってjoinを行っています。慣れていない人にとっては難しいかもしれませんが、古くはperlの連想記憶、最近(これも古いが)の例ではVBScriptのディクショナリに相当します。DBMSを使わないで日常的にファイル処理を行っている方にとっては日常的なコードかと思います。
ちなみに、ADPのコード例ですが非常にすっきりとしているかと思います。C++の例と比べると本来やろうとしていることが明確になっているかと思います。
実行時間は、
D:\>adp -t sql_test_3.p > test3.txt time is 110988ms.
で、約111秒とやはり実験1より速くなっていることが解ります。
こうしてみると、実験2-Bが思いのほか速くなっていないと思わるでしょう。
これはSQLの実行回数に関係しています。
各実験のSQLの実行回数を見てみましょう。
| 実験1 | 1回 |
| 実験2-A | 約470万回(Priceテーブルの行数+1) |
| 実験2-B | 約2000回(Companyテーブルの行数+1) |
| 実験3 | 2回 |
になります。実験2のコードではテーブルの行数に比例した数だけSQLを実行することになります。実験2-Bが実験2-Aより速いのは、Priceテーブルの行数よりComapnyテーブルの行数が圧倒的に少ないから、つまり1対nの結合を行っているからで、仮に1対1の結合では速くならないということになります。
実験3がなぜ実験1より速いかですが、DBMS側から転送されるデータ量が違います。
以下、CSVファイルの先頭5行を表示します。
1717,2005-05-10 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-11 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-12 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-13 00:00:00.000,21251,3522,明豊ファシリティワークス(株) 1717,2005-05-16 00:00:00.000,21251,3522,明豊ファシリティワークス(株)
企業名の『明豊ファシリティワークス(株)』が重複して余分なデータとなっています。実験1のコードではDBMSから言語側にこのように重複したデータが来ます。各実験で転送されるデータ量を見てみましょう。
| 実験1 | 約256MB |
| 実験2-A | 約256MB |
| 実験2-B | 約184MB |
| 実験3 | 約184MB |
実は、DBMSから言語側へ転送されるデータ量自体は、実験1より実験2-Bの方が少なくなります。そのような関係で、実験1より実験2の方が早くなっています。SQLの実行回数(実験1の方がよい)とデータ転送量(実験2の方がよい)になりますが、このあたりはハードウェアの環境やDBMSによって結果が変わってくるでしょう。
この2つのデータから実験3は、なるべく少ないSQLの実行回数で少ないデータ量を転送しているということが解るかと思います。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-02-01 | コメント:0件
Windows2008R2 DNSサーバーで逆引きができない(イベントID:5504)
しつこくWindows2008R2ネタですが、覚書ということで、Windows2008R2に付属のDNSサーバーで、IPアドレスの一部が逆引きができずにイベントビューアーにID:5504が記録されました。また一部で逆引きが通ったりするので厄介でした。
いろいろ探しましたが、結局以下のページ
Forum FAQ: How to troubleshoot DNS Event 5504 error の4番目の解決策の
dnscmd /Config /EnableEDnsProbes 0
でOKでした。
ネットを探すと他にも、
DNS event 5504 - server encountered an invalid domain name in a packet というのがあったのですが、このページにあるShilpesh Desai MSFTさんの『Accordig to KB 198410, it should have non-zero value. - KB198410によるとこのレジストリの値を0以外にする。』に対して、Jharris1993さんが
『Huh? Did you read the KB article? (head in hands, shaking head in wonder) - はぁ、ちゃんとKB読んだ?』
『The correct statement is: According to KB-198410, it should have a zero value if the key exists. - 正しくは:KB198410によるとキーが存在するときはこのレジストリの値を0にする。』
とShilpesh Desai MSFTさんをバカにしていますが、私もKBを読みましたが、Shilpesh Desai MSFTさんの説明は、間違いではないでしょう。なぜなら通常はこのレジストリキーは存在せず、その場合、値zeroと解釈されるので、トラブルシュートを行うならzero以外の値にすべきでしょう。もっともそれでトラブルが解決するとも思えなかったのでこの方法は試しませんでしたが・・・
2011-01-28 | コメント:0件
IIS7.5でクラシックASPの拡張子をASP以外にする
さらにWindowsネタが続きますが、まぁ覚書ということで。IIS6(Windows2003)では、マッピングを追加すれば、クラッシクASP(VBScriptで記述するASP)のファイル拡張子をasp以外(例えばcgiとか)にすることができましたが、Windows2008R2に付属のIIS7.5でかつアプリケーションプールを32ビットで動作させた場合、単純なハンドラの追加以外にちょっとしたひと手間が必要になります。
(1)ハンドラの追加
ハンドラーマッピング『管理ツールから、役割→Webサーバー(IIS)→インターネットインフォメーションサービス(IIS)マネージャ 』から、『サーバー名→サイト→WEBサイト名』で、右ペイン『(機能ビュー→)ハンドラーマッピング』でASPClassicと同様にハンドラを追加します。
ここまでは普通の手順になります。
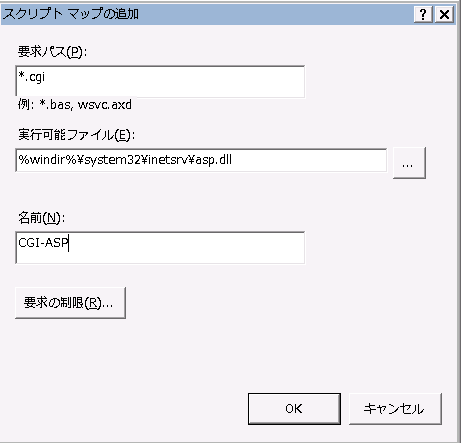
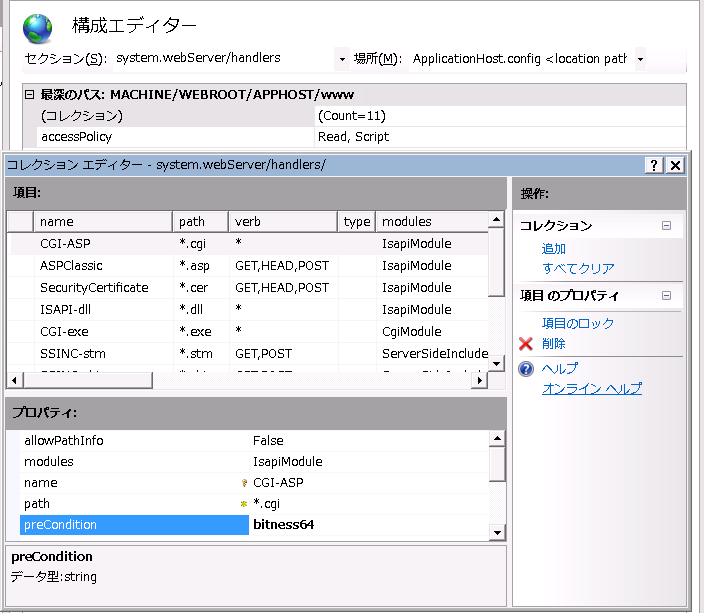
(2)preCondition設定
続いて、同機能ビューから『構成エディタ』を起動します。構成エディタ画面の『セクション→system.webServer/hander』で『コレクション』の行にあるボタンをクリックします。
上のペインで、追加したハンドラを選択し、下のペインにあるpreCondition設定の値を空欄にします(bitness64を削除します)。
2011-01-27 | コメント:0件