PHPのバージョンアップの激しさに閉口する
Wordpressのお知らせで、わざわざPHPのサポート終了について知らせてくれるのだが、Rocky Linux9(要はRHEL9)の場合、PHP 8.0系でも2032年までサポートするらしい。というこで気にはなるが今のところは放置でよい。
もっとも、過去にWordpressがPHP5系のサポートを止めて7系に強制アップデートしたときがありその場合(Centos5か7)の時はPHPのバージョンを気にしないとダメだったので面倒だった。
プログラミング言語のサポート期間が4年とか5年というのは、短すぎると思うのだが、如何でしょうか?
2025-07-14 | コメント:0件
「エンジニアってなんか性格悪い人多くね?」で与太話
Youtubeネタです。
エンジニアってなんか性格悪い人多くね? という記事をみまして、エンジニアとして正論を言うときの注意事項、そもそも営業に仕様を任せることについて、さらに新人教育について与太話します。
2025-03-31 | コメント:0件
RYZEN
2020年もすっかり明けて2月になりましたが、年明けに10年ぶりにPCを更新しました。ちょうど10年ほど前に、購入するPCの世代を統一しようと初代Core i7でソケット1366に決めたのですが、そこからCore i7-980Xを3つ程とi7-920を入手し4台のPCがあるわけですが、その後継ということでZEN2世代のRYZENに決めました。
Core i7を買ったときはちょうどWindows7に乗り換えた時でそこから8,10ときて、ここ2,3年は自分のPCがもっさりしていてグラフィックカードを変えたりしていましたがやっとこさ全とっかえができました。
今回はインテルからAMDに乗り換えたのですが、長いPC歴でちょこちょこAMDを使っています。今までメインマシンで使ったCPUを思い出すだけ書き出すと、こんな感じになります。
1984 (不明)ポケコンPB110
1985 uPD780(Z-80相当品) NEC
1989 80286相当品 AMD
1989 V30 NEC
1992 i486SX(J) Intel
1994 Am486 SX2-66 AMD
1996 Pentium 133 Intel
1997 MMX Pentium 166 Intel
1998 K6 AMD
1998 K6-2 AMD
1998 M2 Cyrix
1999 K6-III AMD
2000 Pentium III 600 Intel
2000 Pentium III 1000 Intel
2002 Celeron 1.4(PentiumIII系) Intel
2003 Celeron 2.3(Northwood-128K) Intel
2003 Pentium4(Northwood) Intel
2004 Athlon 64 3000+ AMD
2006 Pentium D 805 Intel
2006 Core 2 DUO E6400 Intel
2008 Xeon X3350(Core 2 Quad) Intel
2009 Core i7 - 920 Intel
2010 Core i7 - 980X Intel
2020 RYZEN9 3950X AMD
年号は大体ということで割といい加減です。その時の懐事情と趣味とその他諸事情で買い集めたり絞ったりしていましたが、こうしてみると2010年代のスキップぶりが半端ないですね。Core i7についてはSandy Bridge世代でそろえればよかったと少し後悔して、AMDからZenマイクロアーキテクチャが出る噂を聞きつけたときに様子見をしてZen2になったところで「行こう!」となった感じです。
話は戻って、初めての16ビット、32ビット、64ビットCPUは、AMDになります。初めての16ビットパソコンはPC-9801RXでしばらくはIntelを使っていると思っていたのですがあるときに中を開けてみたらAMDのCPUでした。よくよくカタログをみたら80286相当品と書かれていてものすごくがっかりした記憶があります。初めての32ビットCPUは、i486SX(J)と思いきや、このCPUは外部バス16ビットで、それを初めて知った時のがっかり感は半端なかったです。そのあとに買ったパソコンが今はなきコンパックのPresario CDS 524でこちらもメモリの増設で筐体を開けた時にみたらAMDでまたもやがっかりした記憶があります。その後、懐事情が改善し自作に移行して狂ったように買いましたが、初めてのDual-processor, Dual-core, Quad-core, Hexa-core はIntelになります。
RYZEN9は、初めての16-core(書き方を探すのが面倒)、PCI-E Ver4.0(Ver3.0はスキップ)、DDR4-RAM、UEFIです。利用面からは、初めてのCPUプロファイラ(AMDuProf)を使うプロセッサになります。CPUはキャッシュミスとか分岐予測ミスとかが発生すると内部のカウンタで記録をとるのですが、それを読み出すソフトウェアがCPUプロファイラということになります。有名どころではIntelのVTuneがあるのですがこのソフトがめっぽう高くCPUと合わせての購入となると個人では手が出しにくいです。AMDの方はなんと無料ということでまぁAMDということになりました。
そんなものを何に使うのか?と言われそうですが、もちろんADPのインタプリタ部分で、当初はVisualStudio付属のプロファイラを使って最適化を行っていましたが、いろいろ私に合わず、『V-Tuneかー』と思っていたところへ、CodeXL(AMDuProfの前身)の存在を知り、CodeXLに乗り換えたのが5年ほど前になります。CPUがIntelの場合、プロファイラは命令毎にかかった時間が分かるのですが具体的な原因(キャッシュミスなのか?ブランチペナルティか?とか)までは分からずそのあたりは手探りになっておったのがこれでばっちりと分かるようになります。早速プロファイルをしてみると、
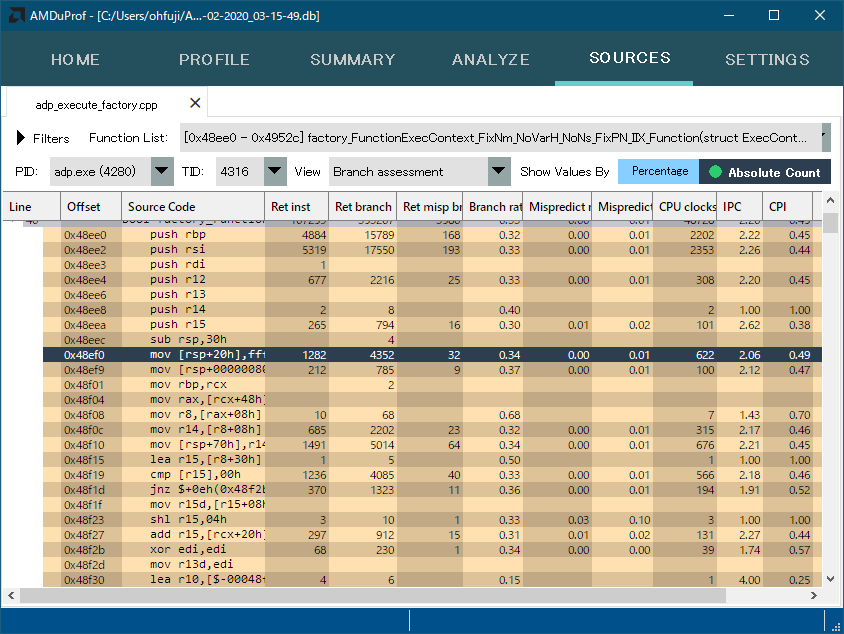
パットと見てよくわからない指標があるのでカウンタの意味についてはお勉強が必要なようです。例えばハイライト部分はただの代入になるのですが、それでなぜRet branchとかが関係するのか?(おそらく他のブランチとの関係で結果的に実行された/なかったとか言いたいのかもしれないのですが・・・)とか直接的でないところがあります。
ここにきて、ADPの実行ファイルサイズは約1MBになりますが、今まではプログラムやデータのメモリへの配置はコンパイラに任せていましたがそろそろそういったところまでも手を出す必要があるのかなと思っています。といっても具体的にどうするのか?という話ですが、先ずCPUプロファイラを使いながら基礎データを集めてその上でソースコードを再編集したり、インタプリタ本体を抜き出してミニマムなプログラムを作ってプロファイルをかけたりいろいろ実験ができそうです。
ちなみにこういった話をすると『じゃアセンブラで組めや!』と言われかねないのですが、まぁうざい煽りに真面目に答えると、要は今のプログラムはCPUの潜在能力を十分に生かし切れていないので工夫の余地があり、上手くいけば数倍早いプログラムが作れるということになり、2020年現在ではシングルスレッド性能で数倍といえば時間軸に置き換えると10年以上先に行けるという話になります。
どういうことかと言いますと、例えば1989年に出たi486DX(33MHz)と2000年に出たPentiumIII(1GHz)の性能比は、単純にクロック周波数で見ても30倍(実際はそれ以上)になります。次いで2010年に出たCore i7-980X(3.33GHz、ブースト3.6GHz)とPentiumIII(1GHz)との性能比は、クロック周波数でみて約3.3-3.6倍と伸び率が10分の1程度に減速しています。そして今回のRYZEN9 3950X(3.5GHZブースト4.7GHZ)とCorei7-980Xはクロック周波数ではブースト時で比較して1.3倍、実際に手元にあるADPのプログラムを動かしてみると整数演算で2倍となっています。つまり、それまでは最新のCPUと言えば以前のCPUより格段に速くなって10年も経てば桁違いの速さを見せたのですが2000年代の中盤頃からそのスピードが止まり、今では10年で2倍のパフォーマンスアップに留まることになります。
つまり今まではプアなプログラムを組んでも時間が経てば解決してくれるのですが、これからはきちんと考えて作らないとダメということになります。
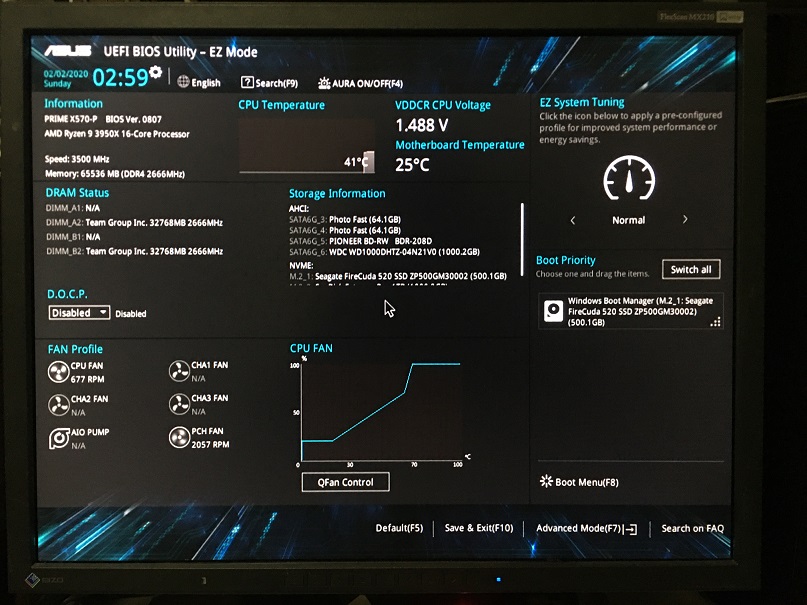
CPUプロファイルの話はこの辺にしておいて、今回もう一つ試したいことがあるのが、仮想マシンの活用で今回、私が使う必要のあるプログラムの一部(eTaxとか弥生会計とか)を仮想マシンの方へ移しました。今までは再セットアップとなるとこれらのソフトを再インストールしなければならなくなり面倒なだけなのですが、それが不要となり気軽に再セットアップができるようになるので便利です。欠点としてはOSやらその他のライセンスがインストールするマシンの台数分必要になることと、RYZEN9 3950X特有かもしれませんがCPUプロファイルとの共存ができない(切替にUEFIレベルで設定変更が必要になる)ことでCPUプロファイルを取りたいときはいちいちマシンを再起動することになります。
2020-02-02 | コメント:2件
オブジェクト指向再考(メッセージ4、メソッドと関数3)
今月も月末に向かって地味に忙しくなって更新が遅れてしまいました・・・。
前回と前々回に分けてダブルディスパッチについて説明しました。前回の繰り返しになりますが、この考えをさらに進めると複数のオブジェクトに対してポリモーフィズムを効かせればどうなるか?という話になります。一般化ですね。もっとも残念ながら、3つ以上のオブジェクトに対してポリモーフィズムを効かせる具体例が思いつきません。まぁ、『3者面談をやった時の先生と生徒と保護者の性格別の対応策』というのも考えられなくはないですが、今まで3つ以上のオブジェクトに対してポリモーフィズムを働かせた実戦経験はありません。ただ、この一般化-マルチディスパッチとかマルチメソッド-というアイデアを頭の隅に置いておくといつか使える日が来るかもしれません。
n体のオブジェクトに対してポリモーフィズムを働かせる。
と考えた場合、『n=0の時はどうなるか?』という考えが湧いてくるでしょう。そうです。n=0の時はメソッドに関係するオブジェクトが無いと考えられます。従来の関数がそれにあたります。
C++は自然に関数が定義できるのですが、JavaやC#は悪名高いpublic staticメソッドを使って関数を定義します。
以上が前回の復習になりますが、さて『関数が必要となる場合』の具体例をあげましょう。こちらもC++のライブラリからになりますが、一般的に以下のようなアルゴリズムの実装はオブジェクトと関係ないということで関数(正確にはテンプレート関数)で実装されています。
・合計値を求める
・ソートを行う
・検索を行う。
JavaやC#のみ知っている方はこの事実に驚かれるかもしれません。が、アルゴリズム+データ構造=プログラムという古典を知っている方なら逆に納得してもらえるかもしれません。つまり、データ構造に対して独立した手続き-アルゴリズムを考えた場合、関数での実装が上手くいくということになります。
それでもまだピンとこない人がいるかもしれません。そういう方はジェネリックプログラミングについて調べてみるのも良いかもしれません。この連載でジェネリックプログラムを扱うのは話が発散するので今は避けますがJavaにしてもC#にしてもジェネリックプログラミングをサポートしていますが、オブジェクト指向プログラミングとは必ずしも相容れるものではありません。
ということで関数(手続き)は、アルゴリズムの実装と相性がいいという話をしました。他には、実はかのstaticおじさんと揶揄されているみながわさんが指摘した、通常の手続きにも関数が使えるという話をします。
さて、みなさんがあるアプリケーションの実装時に、あるURLで指定されたHTMLファイルを取得する必要があった場合、以下の2つのライブラリのうちどれが便利に使えるでしょうか?
関数 gethtml を使う。
URLクラス、URLConnectionクラス、InputStreamクラス、BufferedReaderクラスを使う。
もし、各種クラスを使う方が便利と思うなら、あなたを『オブジェクト指向おじさん』に認定しましょう。
gethtml関数の方が良いのは自明でしょう。もし疑問があるのならコメント欄に質問してください。
さて、次回は変数の共有との関係で関数とメソッドを比べてみます。
2016-04-22 | コメント:0件
オブジェクト指向再考(メッセージ3、メソッドと関数2)
連載も5回目になりましたが、まだモチベーションが維持できています。前回はダブルディスパッチの説明と共にメソッドと関数について本質的な違いはないという説明をしましたが、もう少し突っ込んで話をします。もともと
object.method();
という表記は、methodがobjectのクラスに属しているという意味合いが強いかと思います。言葉を変えるとクラスとはデータと、そのデータを扱うコードが合わさったものという発想です。これはこれで一つの考え方で構いませんが、問題は全てをメソッドにするのも間違いだということです。その一例がダブルディスパッチということになります。以下のように加算演算子+を考えた場合、
object1 + object2
+演算子は
1.object1に所属するのか?
2.object2に所属するのか?
3.両方か?
4.どちらでもないか?等々
1-4の内どう考えるのが自然なのか?という問題に突き当たります。Javaは演算子のオーバーロードを禁止することによりこの問題から背を向けました。つまりこの問題を避けているとも言えます。ちなみにこのような仕様を見たときにJavaは補助輪が付いた自転車のような印象を受けました。C++は『どちらにも属さない』書き方ができます。正確にいうと『object1に属する』の書き方も場合によってはできますが、例えば、
10 + object
のような場合は、『どちらにも属さない』書き方でしか書けません。つまり関数を使ってオーバーロード演算子の定義を行います。C#はある意味『どちらにも属さない書き方』で書きます。つまり、多くのオブジェクト厨が忌嫌うpublic staticメソッドでオーバーロード演算子の定義を行います。
ダブルディスパッチの話を終える前にマルチディスパッチ(マルチメソッド)の話を軽くします。前回、2つのオブジェクトに対してポリモーフィズムを働かせる仕組みをダブルディスパッチと説明しましたが3つ以上のオブジェクトに対してポリモーフィズムを働かせる考え方もちろんあり、マルチディスパッチまたはマルチメソッドと言います。マルチメソッドをいつ使うのか?と言われたらそれはそれで考え込んでしまうのですが、それでも、メソッドが何処かのクラスに属するという考え方に固執するとこのようなパラダイムを受け入れることは難しいでしょう
さて、このようなある種の一般化を行った後は、今度は全くクラスに属さない手続き=関数という存在も自然に受け入れることができるかと思います。つまり、
y = sin(x);
のような式において、文字通りの関数、sinはどのクラスにも属さないと考えた方がよいでしょう。「Mathクラスに入れたらいいだろう」と反論を受けそうですが、実際にsin関数はJava厨が忌嫌うpublic staticで定義されており、C++でも関数として定義されています。先の演算子の例でも出てきましたが、public staticメソッドとは手続型言語での関数定義に相当するものになります。ちなみにかのεπιστημηさんは私との議論で、
Java/C#はどのクラスにも属さないメソッドが作れないため、
当たり障りのないクラス(たとえばMathあるいはModuleC)をでっちあげてそいつに押し込まざるを得ない。
「いかなるクラスにも属さない」という"思い"を表現できません。
僕にはそこが(C++と比べて)不自由に感じます。
というふうに本質的に関数であるものを仮のクラス(Math)に入れることには難色を示されています、これについては私も同感です。
さて、『そんなに関数が重要ならsinとかではなくもっと幅広く使える例を出せ!』と言われそうです。その答えは来週に行うということで。
2016-04-10 | コメント:0件