Previous Page | Next Page
[ADP開発日誌]0.74リリース マルチスレッド化の第一歩 & LLPlanets発表用リリース
ADP公開一周年記念記事がまだ途中ですが、 Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。
実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の,sql@($db,$str,[]).pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
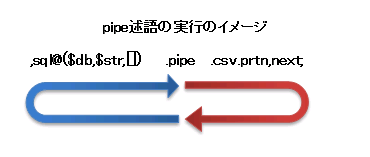
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。

比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
実行時間は、約89秒で実験2と比べて約24%速くなっています。
興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,pipe ,csv($rec,$name).prtn,next;
実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。
| 実験 | 実行時間(秒) |
|---|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-08-19 | コメント:0件
コメントをどうぞ
Previous Page | Next Page