llama.cppの開発&最適化、環境構築
私のAI体験、2026年2月の活動、ということで、我がAIマシン(Core i9-10980XE,メモリ256GB+GeForce GTX1080Ti、GeForce RTX3070)にllama.cppの環境構築を行ったので、そのメモになります。
(事前セットアップ)
- OSのセットアップ、各種ドライバーをインストール
- Cuda toolkitをインストール
インストールされているグラフィックボードのバージョンに合ったバージョンをインストールする。
例)GeForce GTX1080Ti用のCuda toolkitは、12.8.0になる。 - Visual Studioをインストール
Visual Studio 2022 community Editionをインストール - Gitもインストールしておく
llama.cppをダウンロード&ビルド
- https://github.com/ggml-org/llama.cppのページにあるQuick startのBuild from source by cloning this repository - check out our build guideを参照
- ダウンロードは
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp
で行う。 - ビルドのコンフィグレーションを行う
cmake -B build -DGGML_CUDA=ON -DCMAKE_CXX_FLAGS="/utf-8 /EHsc" -DCMAKE_C_FLAGS="/utf-8" -DLLAMA_BUILD_BORINGSSL=ON -DLLAMA_BUILD_LIBRESSL=ON -DCMAKE_CUDA_ARCHITECTURES="61;86"
最後の、DCMAKE_CUDA_ARCHITECTURESの61が1080Ti、86が3070用の設定になる。 - ビルドを行う
cmake --build build --config Release - コードページに関するワーニングがでるが無視しても動作した。一部のツールは文字化けするかもしれません。
動作確認
- llama-serverの実行
llama-server -hf unsloth/Qwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_M -ngl 0 -b 512 --flash-attn on --host 0.0.0.0 --port 8080
ファイアーオールが警告が出たらポートを解放する - クライアントからアクセス
http://(llamaのマシンのIP):8080/でアクセス
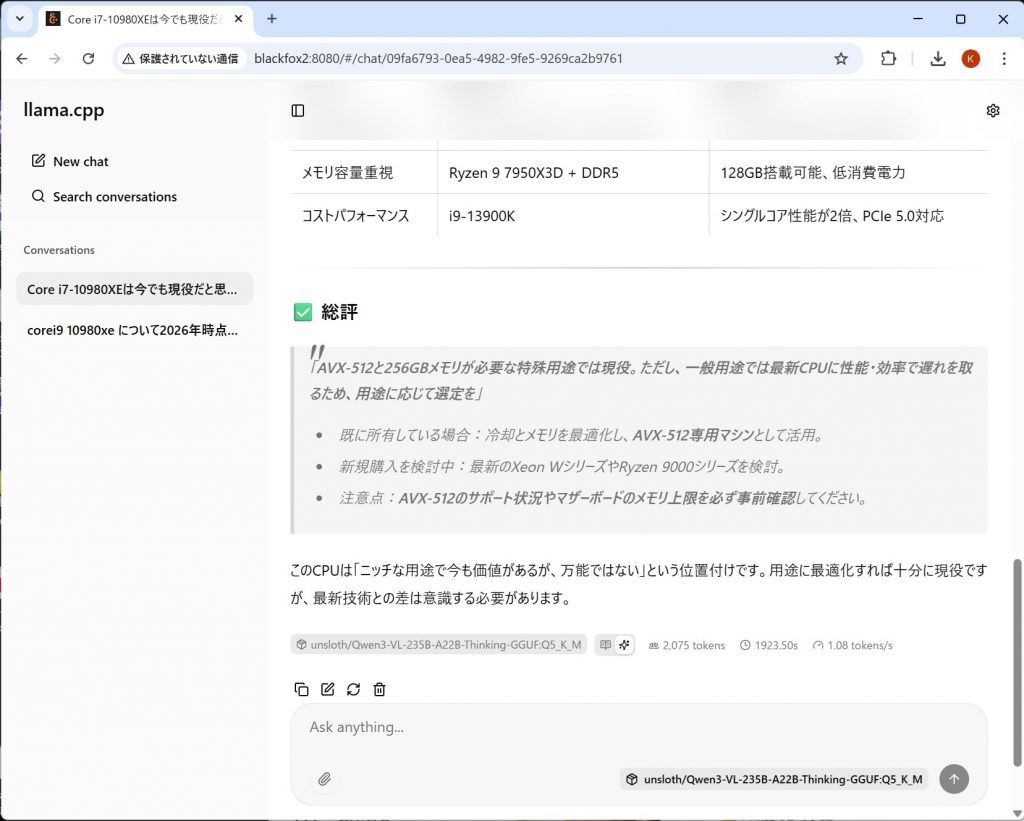
モデルがQwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_Mで、だいたい、1~2Token/sec、つまり1秒に1文字出力される。何かすると20分ぐらいかかるので、これを高速化できればうれしいという話。
Visual Studioからの起動&コンパイル
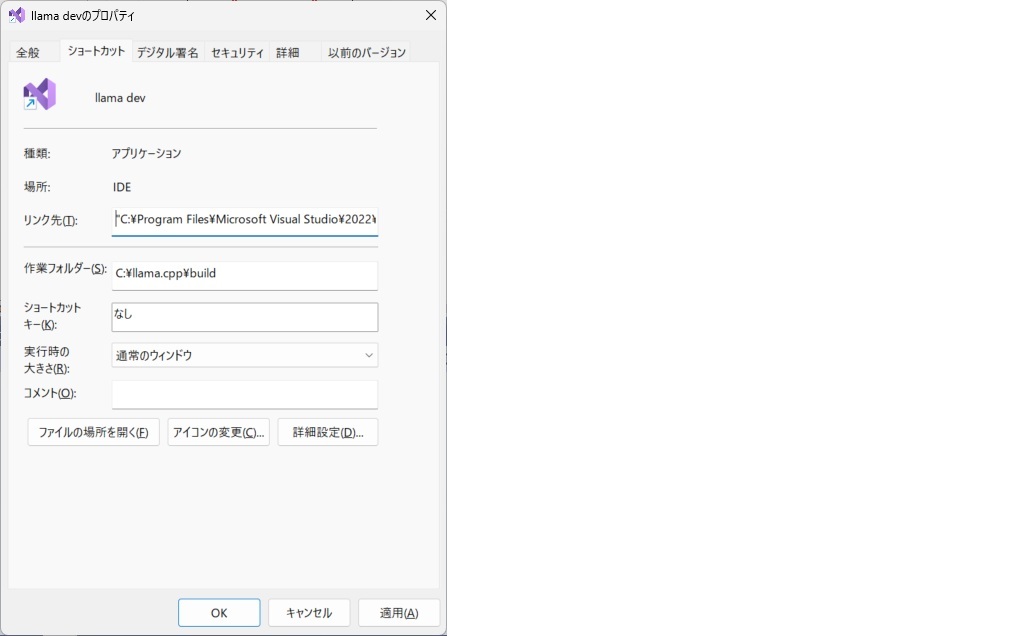
- llama.cppをダウンロードした場所にbuildフォルダが作成される。このフォルダをカレントディレクトリとしてVisual Studio(devenv.exe)を起動する。
下記の要領でショートカットを作っておくと良い
リンク先:"C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\IDE\devenv.exe" llama.cpp.sln (デフォルトインストール)
作業フォルダ:C:\llama.cpp\build (llama.cppをc:\llama.cppにダウンロードしたと仮定)
「詳細設定ボタン」→「管理者として実行」にチェックを入れる(プロファイル時に必要)。
- デバックモードとリーリースモードで、リコンパイルを行ってみる。
VTuneのインストール&動作確認
- VTuneをインストール
使っているCPUに対応したバージョンのVTuneをインストールする。 - VTuneは、最新バージョンしかダウンロードできない。2026年2月現在の最新バージョン2025.8.1.7では、Ice Lake以降のCPUしか対応していない。Core i9-10980XEは、Cascade lake(1世代前)なので対応していない。ので、事前にダウンロードしているもの(2023)を利用する。
- 2022では、Windows11 25H2の環境ではインストールに失敗した(厳密にいうと2024のインストール&アンインストール後に行ったのでそのせいでインストールに失敗した可能性もある)。
- 2024では、正常にプロファイルが取れなかった。
- インストール時のオプションで、Visual Studioのツールにチェックが入っていることを確認すること。
- 先に2024をインストールするとアンインストールしても一部ファイルが残っており、2023をインストールしてもショートカットが2024側を指すので起動しない。
C:\Program Files (x86)\Intel\oneAPI\vtune
以下のフォルダをチェックすること。 - 出来れば、古いバージョンから試して不用意にバージョンをあげない方がよい。
- VTuneの起動
インストールが終了すると、Visual Studioのメニューにアイコンがでるのでプロファイルを行える。 - ソースコードを見るには、プロジェクトの設定でデバッグ情報を出力するようにすれば良いが、デバッグモードで行った方が面倒が少ない。この場合、コードが最適かされないのでパフォーマンスが下がるが、概ね、半分ぐらいの速度になる。あまり遅くなっていない。そもそも手動で最適化を行うのでコンパイラの最適化は止めても大丈夫かと思う。手動の最適化が終わった後に最終的にONにすればよい。
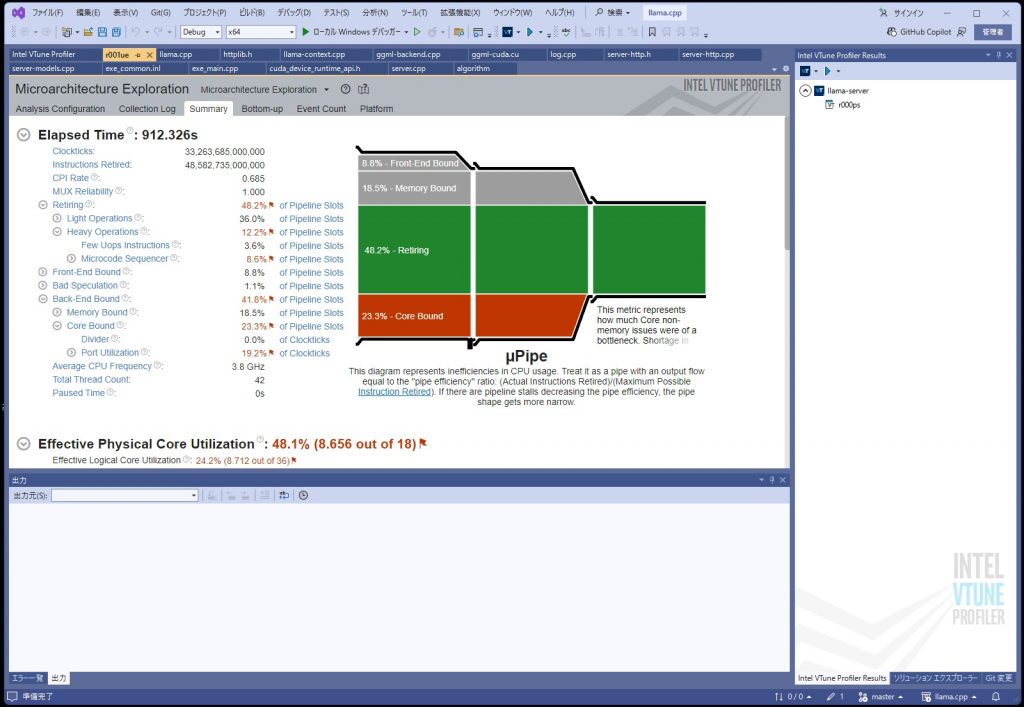
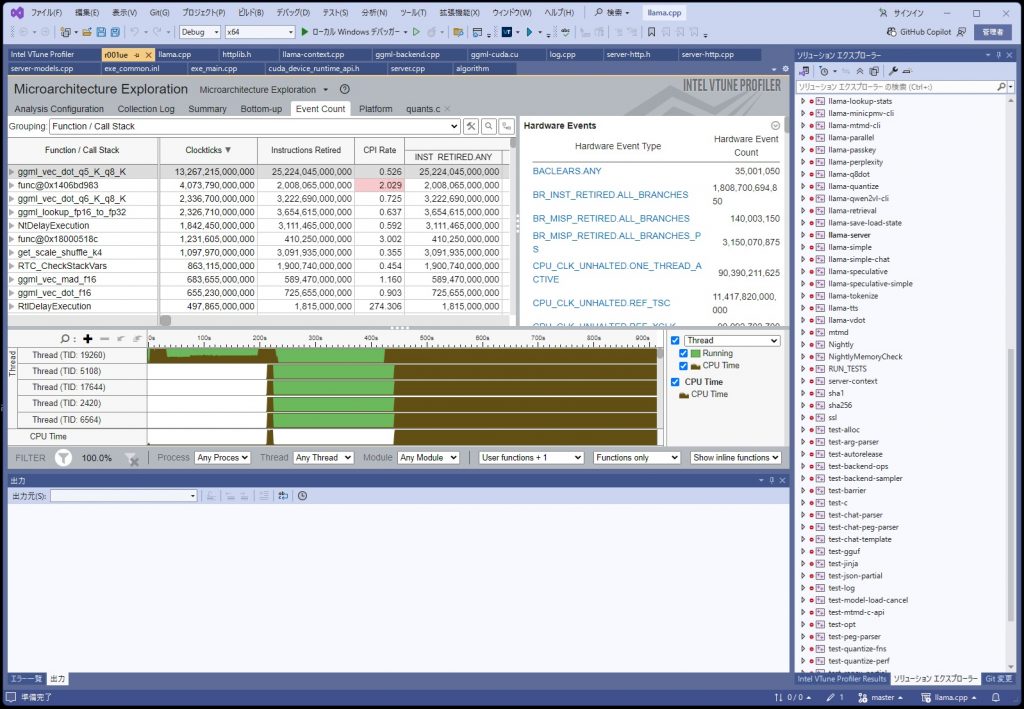
目的の箇所にたどり着けたのでよいが、途中、Bottom-upタブの見方が良く分からないので学習する必要がある。
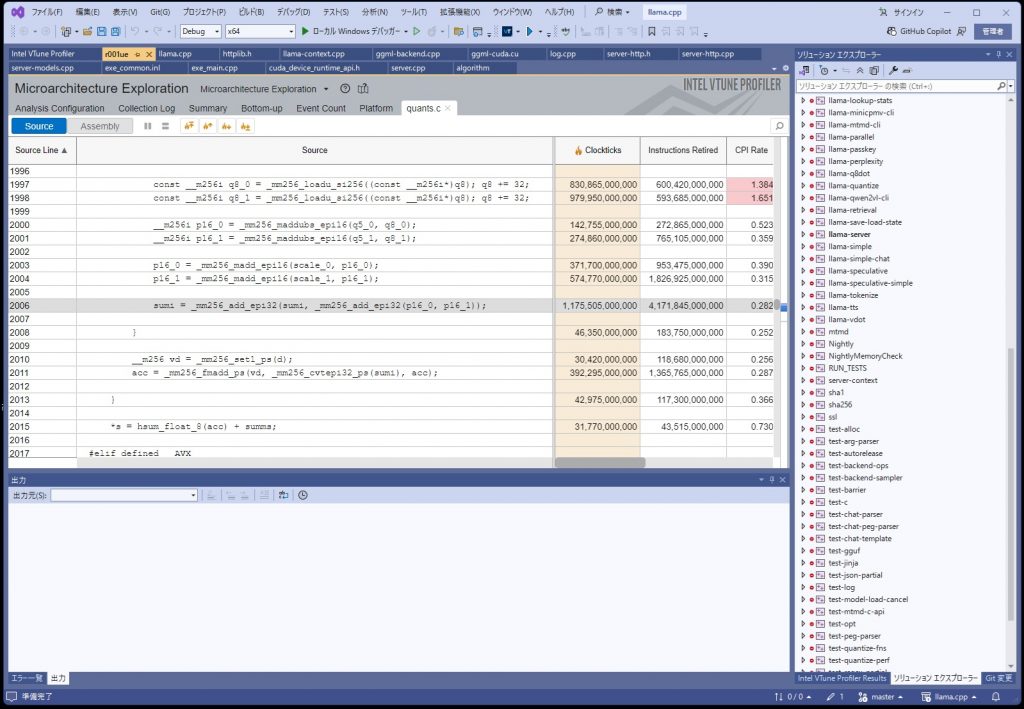
最も時間がかかっている個所が判明したが、
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_1));
どうも、AVX2のコードのようである。まずは、AVX512で動かすにようにして、最適化をかけるようにする。
ボトルネックについて
パット見た感じなので確定的ではないですが、ボトルネックになっているコードは、モデルの重みデータを戻す処理のようである。このモデルデータは、重みが5ビットのものを使っているので内部で8ビットにしているようです。
llama.cppはAVX512を使うといっているがこのデータを戻すところはAVX2のままのようです。
考えてみれば当たり前といえば当たり前なのですが、なんとなく5ビットに圧縮したら展開するのに時間がかかるのではないかと思っていたら、その通りのようでした。この部分の処理時間は全体の約70%ぐらいを占めており、この部分を最適化することは期待がもてる。
もっとも、RAMを大量に積んで利用するモデルを8ビットとかにすればこの部分の処理をカットすることが出来るのでかなり早くなるかと思うが、メモリはこれ以上は積めないので最適化を頑張ろうかと思う。
私のAIショック(2025)
オオカミ少年だったAI
AIという言葉が出てきて早幾年月ですが、いわゆるChatGPT等の生成AIが出てくるまでは、眉唾ものという印象がありました。大昔はパーセプトロンとかバックプロパゲーション、ニューラルネット、ディープラーニングとかいわゆる現在のAIの流れですが、度々ブームで終わっていました。今回の生成AIもバブルと呼ばれているのでそれはそれで何時かはブームが終わるかもしれません。そうなったら、今はAI需要で高騰しているメモリが暴落することになるので買いあさることになるでしょう。その他の流れとして第五世代コンピュータプロジェクトとかProlog、エキスパートシステムなんかもありました。こちらの方はほぼ完全に来ている感はありますが、私はほそぼそとPrologを引き継いだ言語を作っています。
どうやら本腰を入れる必要がある
そんな感じで、AIブームを横目に見ながら、昨年までは、私は主にChatGPTで、英語の校正か、時には説明文(日、英)の生成などに使っていました。私はキャラクターデザインが出来なかったが、ChatGPTでもいい感じのアイコンを生成するのでそのうちゲームでも作ろうかと考えていました。
のんきに構えていたわけですが、昨年春に「もうすぐ消滅するという人間の翻訳について」という記事を読みました。文学系のプロの翻訳家がAI(およびその他)から仕事を奪われる危機感を書いたもので私も共感しました。AIと本腰で向き合わないとダメだということで、向き合うことにしました。
まずは、ローカルLLMということで、AI用のマシン(Core i9-10980XE,メモリ256GB,グラフィックカード Geforce RTX 3070 + GTX1080Ti)、を用意し、llama.cppをインストールして、いくつかのモデルをダウンロード実行し、WEBアプリ(ゲームを想定)を作らせたりしたが、残念ながらまったくお話にならないくらい完成しなかった。よくある「直しました」と言って直ってこないことが多々あった。
ここで、バイブコーディング用のAIを使えばよかったかもしれないが、フリーのモデルの精度が向上することに期待する。
その後、Youtubeがおっくう(動画編集が面倒くさくなり)、6月ぐらいからブログの方にシフトしていたが、徐々にChatGPTとの共作を模索するようになった。
最初は、過去の記事をChatGPTに読ませていたが、そのうち試しに記事を書かせてみた(原稿を私が書いて、ChatGPTに原稿を元に肉付けをした)。ただ、ChatGPTの文章がいまいち気に入らないので、ChatGPTは校正・批評をさせるようにした。今のところAIに何かを作らせるより、批評をやらした方が『AIは、何を知っていて、何が出来て、何が出来ないか』が解るようになると思ってやっている。
ちなみに、私の記事の中でのトップ2をChatGPTに評価させました。
社会人であり、技術者であり、とChatGPTの評価の評価になります。
話は少し脱線しますが、この記事はStaticおじさんのパロディーとして馬鹿にするWEB小説が出たことに対する警鐘としてこの記事を出しましたが、ChatGPTも指摘していますが、2026年現在、この記事の主張は正しいとChatGPTは言っておりますね。このあたりをまた記事にしたいですね。
昨年末あたりから、GeminiとChatGPT体制で「校正・評価」をしていたが、そのうち、Gemini,ChatGPT,Grok,Copilotを使うようになりこれらの共通するものを探るようになりました。
2026年1月の各種AIの雑感
以下、私のこの半年で真面目にAIを使った結果、各種AI(無料版)の2026年1月時点の雑感になります。
全体評価について。今AIと言われているものはLLM(大規模言語モデル)を主に使っていることになりますが、言葉(言語)の運用(日本語や英語、翻訳)についてはほぼ信頼に値するかと思います。
加えて、元がネットからの情報収集ということもあり、ネット民の気持ち(?)については良くも悪くもAIは把握している模様。AIに小説やライトノベルを書かせて、いいところまで行っているケースもニュースや記事で見るようになった。一方で、「最近のnoteはAI記事の巣窟」と言われるとおり、質の悪いAI記事に埋もれている。人間とAIが上手く連携しないといい記事にはならないということのようである。
一方で、コンピュータ(プログラミング)関連については、海外の標準的な知識があると思われる。ITのQAサイトのStack Overflowの質問件数が激減しているとのことで、つまりある程度のQAについては、既にAIによって回答が可能というところまで来ているようである。
ちなみに、AIは良く嘘をつくというが、ITに限るとStack Overflowの例もあるとおり、既に平均的な人間のエンジニアよりAIの方が良いのではないか?と思われる。
私の記事に対しても、そこらのエンジニアより的確なツッコミを見せていた。
ただし、キーワードを拾ってそれを上手くつなげている感(表層的な議論)はぬぐえない、ちょいちょい突っ込むことになる。のでやはり限界が見えてきた。
各AIの個性を見てみる

Gemini
一番、おべっかを使ってくる。こちらが反応してほしいワード・文章を拾い上げるのが上手い。モチベーションが上がる挨拶を入れてくる。IT系についてはきちんと学習させている面がある。
ChatGPT
Geminiと比べておべっかが若干下手。ただしGeminiより批判と改善案をより出してくる。IT系についてはきちんと学習させている面がある。
Copilot
基本ChatGPTと同じ、若干おべっかが過ぎるか。IT系についてはきちんと学習させている面がある。
Grok
一番おべっかを使ってこない。批判するときは、「これは主観的」、「データがない」、「ハルシネーションについての考慮がない」等、どうも予め決められた批判をしてくるようである。Xの投稿や政府の発表を鵜呑みにする傾向がある。
SNSを見ると「AIが嘘をついた」といって騒いでいる人がいるが、そもそも情報に関しては裏どりをするのが基本で、裏どりもせずに「AIが嘘をついた」というのもどうかと思う。(まぁ、そもそもSNSの情報を信じてはダメなので・・・)。私としては人間がつく嘘と同程度だと思われる。
AIを使っての野心
チャットベースのAIですが、今後の進化として、ある製品を作ったときにセットでAIチャットを用意するということが考えられます。具体的には、私はプログラミング言語(ADP)を作成しているが、ADPを学習したAIに、コードを生成させたり質問に答えさせたりすれば独自言語の学習のコストを下げられるようになるかと思う。実は、AI時代には独自言語の開発は難しくなったかと思っていた。つまり今のAIは現在ある多くのプログラミング言語について既に学習しているが、対して私が開発した言語についての知識はない。これは言語の普及を考えたらマイナスかと思うが、いわゆるファインチューニングでADPを学習させれば良いと思いなおした。ちなみにChatGPTに「独自言語を普及させるには?」と質問したら、「ドキュメント」やら「サンプルプログラム」やらを進めてくるが「AIに学習させるのはやめた方がよい」と返された。ChatGPT自体は、AIがプログラミング言語を学習するのは難しいと結論づけているのが興味深い。
今後のネットの情報について
Stack Overflowの質問件数が激減とかnoteはAI記事が氾濫しているということを鑑みると、人間の良質な記事やアイデア、プログラムのソースコード等、いわゆる知的財産というものについてはネットに出てこなくなるかと思います。私についても何気なく公開したプログラムを「人が見るよりも早く」AIのクローラーに収集されて感じたのは「もう不用意にコードを公開するのはやめよう」と思いました。もちろん公開しても良いコードは公開しますし、記事は書いていきますが、やはり今年はローカルLLMを鍛え、知的財産の保護をしつつメジャーなAIに比肩できるAIの運用にも力を入れたいと思います。
AIは人間を超えるか?について
触ってみた感触ですが、現在のAIは人間を超えるのは難しそうです。もちろんですが、各分野について素人を超えたパフォーマンスを見せるので思わず「おっ」となりますが、人間の真の創造性(要するに0から作るところ)の模倣については難しいのではないかと思う。もちろん今後の発展次第ということも言えますが。
生成AIとのやり取りで、「知能とはなにか?」とか「真理とはなにか?」ということを思い知らされます。Grokは、Xや公的機関の発言を鵜呑みにしているところがあり、他のAIについては各社がファインチューニングをしているようである。つまり、AI自体が「これは正しいか?」という判断は出来ないようで予め「これは正しい」と学習させている。この場合、いわゆる哲学や社会科学系のように客観的に真理が解らないもの(と私が思っているのですが)についてはAIは正しいやり取りは出来ないのではないか? 例えば2026年1月現在でいうと今の自民党政権で景気は浮上させることができるか?とかに答えるのは難しいかと思われる。
その他の点であるが、ある種の閃きというのがAIからは感じられない。現在のAIは、いわゆるニューラルネットということで人間の神経細胞を模倣しているが、どうも私自身の思考のメカニズムを振り返るとニューラルネットとは別の仕組みがあるように思える。具体的に言うと量子コンピュータのようなものになる。例えば、プログラムのアイデアだったり、わけのわからないバグの原因が突然、閃いたりするがそういうものはどうもニューラルネットではなく、より高次元の演算が脳内に起こっているような気がしている。
この仮説が正しければ人間はしばらくは大丈夫だと思う。
なぜ日本のITが弱いのか?(もう一つの理由 Part1)
- ITに関わる日本人は英語が残念なことが多い -
ITの権威も英語は弱いか?
変数名は「AIにレビューさせろ」Part1で、「日本人の英語力は、ばらつきがあり変数名の命名に英語を使うときは危険度が増します。」と婉曲的に書きましたが、残念ながら少なくともITに関わる日本人の英語力はやはり残念なことが多いです。
これは、私自身の英語力も以前は残念だったといえますし、今は「残念でない」だけで、上手いか?と言われたら「人よりは」と謙遜してしまいます(一応プロなので)。
実は、プログラマになりたい人向けに、「基本情報技術者試験の科目B」をお勧めしたのですが、その問題文に「残念な英語」が混ざっており発見してしまいました。
令和5年度、基本情報技術者試験 科目Bの問1の
論理型: divideFlag
になります。この変数は回答に関わっており、あまりいい加減にしてほしくないのですが、何が問題かというと命名はこの際置いておいて、値(true/false)の持たせ方にあります。
if (divideFlag が true と等しい)
pnListの末尾 に iの値 を追加する
endifとありますが、divideFlagを素直に読むと「割算フラグ」ということで、値がtrueの時はどういう意味かが曖昧になります。
コード上では「true = 割り切れていない」という意味ですが、多くの人は「true = 割り切れた」と受け取ってしまうでしょう。つまり誤解を与える使い方になっています。
ということでAIに掛けてみました。各AIの実行結果は以下のとおりですが、全AIが『意味があいまいになる。「割り切れた=trueと解釈しがち」』としています。
ChatGPTの結果
Geminiの結果
Copilotの結果
Grokの結果
ちなみに、ChatGPT,Gemini,Copilotは、「命名が良くない」とも指摘しています。
ChatGPTは下記のとおり1回鍛えたのでより突っ込んだ内容となっていますが、いずれにしても、divideFlagはダメということになります。
私自身は、『i ÷ j の余り が 0 と等しい』の条件の部分を無意識に『i ÷ j の余り が 0 と等しくない』が正解と考えてしまい、「答えが無いやん!」と一瞬混乱しました。
もっとも、恐らくほとんどの方が、「私がおかしい」と指摘するでしょう。この部分ですが、「割り切れたら後の追加は不要(false)」という意味(candidateFlagやisPrimeなど)であればまったく問題なく、アルゴリズムを適切に判断すると、 『i ÷ j の余り が 0 と等しくない』という認識がおかしいということになります。ということで『私がいちゃもんをつけている』と感じる人もいるでしょう。要は各人が持っている英語力ということになるのですが、今は、AIで試すことにより、一部のエンジニアのいちゃもんなのか、正しい指摘なのかを確認できる時代になりました。
日本のITエンジニアの英語力
普通のブログ記事なら「IPAさんやってしまいましたね!」と言って終わりでしょうが、いくら何でも「試験問題」ということでそれなりに注意して作成はしているでしょう。実際に多くのITエンジニアは私のような混乱は起こさないかと思います。つまりこのあたりが我々ITエンジニアの英語力の限界と考えた方がよいです。つまり、「AIにレビューさせろ」Part1の正しさをIPAさんが身をもって証明していたとも言えます。
ということで私は、日本語でプログラムを組めるようにしたいと改めて思いましたので、ADPは日本語で名称を記述できるようにしたいです。
「変数名を日本語で・・・」を読んだ硬派なITエンジニアは「変数名は英語だ!」と主張するかもしれません。そんなあなたにはTOEICや英検の受験をお勧めします。おそらく適切な英語名の命名に必要な英語力は、TOEICで730点、英検準1級以上かと思います。100歩譲って、TOEICの平均点560(英検2級程度)であれば、なんとか命名が出来るかもしれません(私の主観では足りないかと思いますが)。もし受験していない人は受験することをお勧めします。おそらくショックな点数(例えば300点)とかになるかもしれませんが、普通のITエンジニアの英語力はそんなものです。
やはりAIレビューが必要
この問題は令和5年(3年前)になりますが、今ならコード全体をChatGPTに掛けられます。下記のとおり、divideFlagについてダメ出ししてもらえるので、今後は試験問題をAIに掛けたいです。ただしローカルAIでレビューしないと思わぬところで問題が漏洩する可能性があります。
ちなみに、コードにある i,jのような1文字変数は『ダメ』という記事も見かけますが、「AIにレビューさせろ」Part0(初心者の方へ)で指摘しているとおり現実としてよく使います。また、ChatGPTはダメ出ししていません。つまり、1文字変数は普通に使うと考えた方がよいでしょう。
さらに、divideFlagのように混乱を助長するような命名を行うのであれば、むしろ f のような1文字の名称の方がましだと思いますが、それはまた別の話ということで
変数名は「AIにレビューさせろ」Part2(税込価格の回答例)
前回、前々回で、概ね言いたいことは言ったので与太話的にはOKなのですが、多くの日本人プログラマが経験するであろう業務アプリの開発を想定した変数の命名について、「アーキテクト」的な補足を行います。
前回、前々回の記事の要点をいうと「命名は主観的になりがちなので、ルールを決めない状況でのレビューは危険」、「初心者は先ずはプログラムを書くことを学習する」ということを言ったのですが、今回の要点は、広域だったり業務用語に対応する変数の命名というのは、「個人の主観ではなくチームとしてきちんと定義しましょう」という話になります。
コーディング規約とともにある「プロジェクト用語集」
コーディング規約については既に説明しましたが、一言でいうと「命名についての一般ルール」で主にスタイル(単語の書き方や熟語の書き方が主軸)のルールになるかと思います。
一方で、「プロジェクト用語集」なるものも存在します。これは、プログラマが予め知っておいた方がよい、専門用語や業務用語についての項目と説明があります。
プロジェクト用語の代わりとしてのDB定義書とその項目名のAIレビュー
もっとも、実態としては「カバーしている用語の数が少なかったり」「ピント外れ」だったりもありますし、多くのプロジェクトでは「そんなものは存在しない」です。実は「プロジェクト用語集」に準じるものとして、「データベースの定義書(スキーマ)」が挙げられます。例えばECサイトなら、商品テーブル、注文テーブルなどがあり、以下のようになるでしょう。
商品テーブル:Goods
商品ID(id)
商品名(name)
単価(price)
注文テーブル(Orders)
注文ID(id)
注文主氏名(orderer_name)
送付先氏名(shipping_name)
送付先住所(shipping_address)
送付先電話番号(shipping_tel)
税抜価格(sub_price)
税込価格(tax_price)
送料(sipping_fee)
合計価格(total_price)
注文明細テーブル(Order_items)
注文明細ID(id)
注文ID(oid)
商品ID(sid)
個数(number)
税抜価格(price)
(当たり前ですが、細かいところは端折っていますが)、最低限、このような項目があるかと思います。
まったくの初心者の方はついてこれないかと思いますが、送付先とか送料、合計価格などの名称は馴染みがあるでしょう。各々の項目に英語名がカッコ内にあります。大体、この英語名がDBのカラム名(テーブル名とあわせて、グローバル変数名のようなモノ)になります。今回はこの英語名をAIでレビューさせます。
さて、これをChatGPTにかけた結果がこちらになります。
https://chatgpt.com/share/695f48aa-9450-8006-ae08-f7941ab5e69c
上記はChatGPTとのやり取りですが、ChatGPT,Gemini,Copilotでレビューした結果(それぞれの推奨の名前)を表にまとめます(やり取りの詳細は省略します)。
| 元 | ChatGPT要修正 | ChatGPT推奨 | Gemini | Copilot |
| Goods | products | products | products | products |
| name | - | - | - | - |
| price | - | unit_price | unit_price | - |
| Orders | - | orders | orders | - |
| orderer_name | - | customer_name | customer_name | customer_name |
| shipping_name | - | - | - | - |
| shipping_address | - | - | - | - |
| shipping_tel | - | - | - | - |
| sub_price | - | - | - | net_price |
| tax_price | - | - | - | gross_price |
| sipping_fee | shipping_fee | shipping_fee | shipping_fee | shipping_fee |
| total_price | - | total_amount | total_amount | - |
| Order_items | - | order_items | order_items | OrderItems |
| oid | - | order_id | order_id | order_id |
| sid | - | product_id | product_id | product_id |
| number | - | quantity | quantity | quantity |
| price | - | unit_price | price_at_sale | - |
| - | - | subtotal_amount | - | - |
さて、このようにデータベースの定義ができますとおのずと、「これらを扱うプログラム」で上記のカラム名に対応する変数名は、当然カラムの英語名を使うことになります。ORMを使えば自然にそうなりますし、手でSQLを書くことになっても敢えて違う名称にする意味はないだけでなくバグにつながるでしょう。
もちろんですが、これは「ある種の理想論」になります。現実的には「カラムの追加削除や変更」があり、それに伴い、プログラム上の変数名とDBのカラム名が時間と共に徐々に異なっていくこともあるかと思います。それを直すかどうかはまた別問題になります。
レビュー時のプロンプトについて
プロンプトの与え方ですが、私の意見になりますが、このように「関連するものはまとめて問い合わせる」方がよいかと思います。サンプルはDBのテーブル定義になりますができれば全部を与えます。プログラミングの場合(作成したプログラム全体)を渡した方がよいでしょう。
これによりAIが、意図を理解して用語間(変数間)の調整も考えてくれます。
感触になりますが、バイブコーディングが実用化されようとしている現在、このような割と突っ込んだ問い合わせにもAIはちゃんと対応できます。
ちなみに、私の場合のように「ある程度名前が用意できる」人はプロンプトとして、
「致命的な間違いを指摘してください」、「海外でも通用する名前を提案してください」
とかにすれば良いかと思いますし、まったく名前が思いつかない人は
「英語名を提案してください」
とすればよいでしょう。
AIの評価について
表を見ますと
・致命的なもの、誤字(sipping_fee)
・不適切なもの(Goods, orderer_name, sub_price, tax_price, number)
・推奨されるもの(price → unit_price)
があります。命名は主観と書きましたが、AIも同様に個性があるようで微妙に違うのもがあります。これらをどう処理するかは、話し合って決めることになりますが、基本的には、誤字や誤訳のように致命的なものを直せばよいかと思います。
英語にない日本語名の訳について
ちなみに、tax_priceですが、表には出ていませんが、price_with_taxやgross_priceがあるのですが、そもそも「税込価格」という直接の対訳が無いようです。この対訳が無いという判断はAIではちょっと厳しいかもしれません。このあたりは命名を行う人の英語力ということになります。要はprice_with_taxのようにいかにも説明的な訳だったり、gross_price(合計金額)のように漠然とした訳を見たときに、『「税込価格」というのを海外ではあまり使わないな』と判断するのですが、これはこれで業務知識と英語力が問われるところです。
日本の場合、
・税率の違い(8%、10%)
・外税表示、内税表示がある
などがあります。海外でのこのようにしている国もあるのかもしれませんが、英語の名称(いかにも説明的な訳)を鑑みるとどうも税込価格と税抜価格をいちいち用語として区別することがないように感じられます。これらを踏まえて、ChatGPTと対話してみました。
https://chatgpt.com/share/695f63c1-7ef8-8006-a943-9e946dfce54c
完璧ではないですが、税込価格、税抜価格の候補として、
price_including_tax / price_excluding_tax
tax_included_price / tax_excluded_price
price_with_tax / price_without_tax
gross_price / net_price
base_price / total_price
があるようです。「これ!」という一組でなく、いくつもの組み合わせがあるということで、どれにするのかを決めるとともに、「このように変数名に対して複数の候補が考えられるときは、メンバー各位に命名を任せたらばらつく可能性がある」ということもプロジェクトリーダー・マネージャは頭に入れる必要があるかと思います。
Part2のまとめ
まとめますと
・データベースと関連付けられた名称や、グローバル変数等、複数の人間が関与する変数名は予め決めておいた方がよい。
・税込価格など「専門用語」の場合、対訳も専門用語の対訳にした方がよい(ただし常に対訳があるとは限らないので臨機応変にする必要がある)。
・複数の対訳が考えられるときは「どれを使うのかを」決めておく。できれば使わない候補を(使わない変数名)とすると無用な混乱を事前に防ぐことができる。
・人が作るアプリケーションは大体決まっていることがあるので、慣用表現(GoodsではなくProducts)があればそちらを使う
ということが言えるかと思います。
アーキテクトの仕事
あまり明確に言われていないかもしれませんが、以上のように考えながらスキーマ設計を行ったり、用語集の必要性を考えるのがシステムアーキテクトの仕事の1つになります。
変数名は「AIにレビューさせろ」Part0(初心者の方へ)
変数名は「AIにレビューさせろ」Part1を公開したのですが、同時にAIから
「これは初心者向けの記事ではないのでは?」
と散々、指摘を受けたので初心者とスクールで教えようとしている方向けに補足を行います。どちらが最初でも構いませんが、初心者の方は本記事を最初に読んだ方がよいかもしれません。
初心者の方
例えばですが、Google C++ スタイルガイドや、Linux Kernel 2.6 Documentation- CodingStyle を参照してみてください。変数名の記載の項目になります。
何を言っているかわからないかと思います。それが答えです。
という、哲学的な問答はやめてストレートに言いますと、「まったくの初心者の方は、まずはプログラミングの書き方を学習するべきであり、コーディングスタイル(変数の命名だけでなく、あるべきコードの書き方の基準)は、後回しにしてもかまわない」ということになります。つまり今は考えなくてよい(もし気になるのならAIに聞け)ということになります。
それでも、気になる方はもう一度Google C++スタイルガイドの「命名規則」を読みましょう。引用しますと、
・命名に関するスタイルルールはかなり恣意的なものです
・あなたにとってわかりやすいと感じるかどうかに関わらず、「ルールはルール」と考えるようにしてください。
ということです。これの意味するところを大げさにかくと、「変数名は「AIにレビューさせろ」Part1」の記事になります。
加えて、日本人に対する補足を行います。(通訳案内士の観点になりますが)、日本人というのは「言われなくても規律を守る」民族のようで、一方で欧米(というか民主主義の国の人は)、「自由が基本、必要ならルールを作る」という文化的な違いがあります。主にアメリカからくるルールを日本人に当てはめると、必要以上に日本人が守りすぎるという傾向があるので注意しましょう。という話です。
初心者から脱しようという方
上記の2つのスタイルガイドをみて、「言っていることは解る」という人はもう、命名規則については卒業ということになります。
「これでは不安」だという方は、一つ卒業試験をしましょう。上記の2つのスタイルは真逆のことを言っている部分がありますがどれでしょうか?
私が見つけた正解の1つは、
Linux Kernel 2.6のコーディングスタイルは、変数名の省略を許容しており、Google C++の方は許容していないということがあります。
(もっともどちらのスタイルもループカウンタは i でよいとしています)。
私の観点(理解)になりますが、これらの違いを補足すると、カーネルは基盤ソフトウェアで、Googleが作ろうとしているものはアプリケーションということも言えます。
コーディングの文化というか、作成しているもののレイヤーが異なります。
例を挙げると、変数の値を交換する swap関数 というものがありますが、Linuxの方はswap関数を作る方、Googleの方はswap関数を使う方ということです。
swap関数を C言語風に 書くと
void swap( int *a, int *b) {
int t = *a;
*a = *b;
*b = t;
}
となるかと思います。ここで、a,b,tと出ましたが、これに対して「変数名が、意味のない1文字だろ!」という人は(0ではないかと思うが)私の周りではいません。逆にここで変数名に対してとやかく言う人とは距離をとった方がよいです。(実は変数名以外には問題があります。ヒントは型、エラー処理あたりです)。
一方で、Googleの方は、swap関数を使う側、例えば、
swap( oldMachineStatus, newMachineStatus);
と言ったコードにフォーカスを当てているということになるかと思います。
言っていることは解るが釈然としない(初心者の方)
コードコンプリートやリーダブルコードなど実績のある書籍を読むことをお勧めします。
「1文字変数はダメ。booleanは○○。」と言ったような断片的な情報ではなく、「なぜこのように命名すると良いのか?」についてできるだけ主観を抑える努力を用いて書かれているでしょう。
また、上記のようなスタイルガイドも併せて読むことを勧めします。書籍やガイドによって矛盾点が見つかります。それに対して『自分はどうするか?』と自問してみましょう。
2026年現在確認できる多くのコーディングスタイルでは、ループカウンタには i でよいとしていますが、意味のある名前にしましょうという書籍もあるようです。「○○にこう書いてある」ではなく、あなたの正解を見つけてみましょう。
「能書きはいいからお前はどうしているんだ?」という方
(Grokの指摘を受けての追記)私自身ですが、アマチュア時代を入れると40年以上プログラミングをやっており、使った言語も、BASIC、アセンブラからC/C++、Java、perl, php, Ruby、python, ADPと多岐にわたるので、「これ」と言った基準はないです。と言っても傾向はあるのでご紹介します。基本的にlinuxのコーディングガイドが近いかもしれませんが、業務アプリも作成するので混ざっています。下記を見てもらえますと私が「1文字変数はNG」、「booleanはis/has」と言われると反発する理由が良くわかるかと思います。
- 慣例、ルールがあればそれに従う。自分で作る場合は英語で名称を考える。
- 名前付けの優先順位
グローバル変数、メンバ変数、引数、ローカル変数の順で優先順位が下がる(適当な名前でよい)
グローバル関数名、クラス名、メンバ関数名の順で優先順位が下がる
※名前空間は今のところ使用していないが、徐々に意識するようにしたい。 - 変数名は名詞が基本、もちろん内容によって形容詞、動詞を使うこともある。
- 関数名、メソッド名は動詞が基本、以下同様
- クラス名は、名詞が基本、以下同様
- 1文字2文字変数については、ローカル変数で慣用的に使うことがある
a, b, c ・・・抽象的な値を表現するとき
v1, v2, v3 も同様に抽象的な値を表現するとき
c, cnt ・・・ ループカウンタ
f, flg ・・・フラグ、fは、まれにファイルポインタでも使う
h ・・・ ハンドル(低レベルI/Oが返すIDのようなもの)
i, j, k, l, m ・・・ループインデックス
n ・・・ (next)の略
p, q ・・・ ポインタ
s ・・・ 合計
t ・・・ テンポラリ変数、時間(秒)
k / v ・・・ (マップの)key value
u ・・・ ユーザID
r ・・・ 戻り値
x, y, z ・・・ 座標
そのほかテンポラリ性の高い変数は、英単語の先頭1文字の名前を付与することもあります。 - 略称、非略称
DBのカラム名、グローバル変数、グローバル関数、クラス名のようにグローバル性が高い名称は非略称、その他は適宜略称を使う - 単語の区切り
複数の単語を区切るときの作法として、キャメルケースを使うか(区切りで大文字にする)、スネークケース(アンダーバー'_'で区切る)かがある。
モダンな言語(Java以降)はキャメルケース
アセンブラ,C,C++は、スネークケース
グローバル変数、グローバル関数、クラス名はキャメルケース、ローカル変数、メンバ変数はスネークケースと混ぜて使うこともある。
略称変数の場合、そのまま結合することやプレフィックス、ポストフィックスとして使うこともある。
nstatus
namep - 業務アプリの例はPart2を見てもらえればと思います。
実践
さらに、実際のコードがどうなっているかを調べることも重要です。
以下、Linux kernel 6.18.3 で適当に選んだファイル(acct.c)からの変数名(と引数名)を出現順で10個を列挙します。
acct
sbuf
p
ns
res
pin
work
acct
file
name
私には大変馴染み深い名称ですが、皆様どうでしょうか?
これだけだと何なので、同プロジェクトから適当に選んだpythonのファイル(check-perf-trace.py)からの変数名(引数名)を10個ほど列挙します。
event_name
context
common_cpu
common_secs
common_nsecs
common_pid
common_comm
common_callchain
vec
call_site
理解できるかはともかく、分かりやすい名前になっているかと思います。
それでもモヤモヤする人
ここまでで述べていない論点としては、「プログラミング言語」の言語的な側面があります。我々は言語を使うときに「単語」を使っておりますが、いちいち命名をする機会はあまりないかもしれません。命名と言えば、子供の名前など「固有名詞」が頭に来るかもしれませんが、どちらかというと「数学や物理の計算式の変数」だったり「作文の章立ての題名」だったり「その間の感覚のもの」だったりします。いずれにしても「内容を簡潔に説明するもの」として命名が存在しますが、プログラミングは文学ではないのであまり深入りはやめましょうという話になります。
変数名は「AIにレビューさせろ」Part2(税込価格の回答例)