llama.cppの開発&最適化、環境構築
私のAI体験、2026年2月の活動、ということで、我がAIマシン(Core i9-10980XE,メモリ256GB+GeForce GTX1080Ti、GeForce RTX3070)にllama.cppの環境構築を行ったので、そのメモになります。
(事前セットアップ)
- OSのセットアップ、各種ドライバーをインストール
- Cuda toolkitをインストール
インストールされているグラフィックボードのバージョンに合ったバージョンをインストールする。
例)GeForce GTX1080Ti用のCuda toolkitは、12.8.0になる。 - Visual Studioをインストール
Visual Studio 2022 community Editionをインストール - Gitもインストールしておく
llama.cppをダウンロード&ビルド
- https://github.com/ggml-org/llama.cppのページにあるQuick startのBuild from source by cloning this repository - check out our build guideを参照
- ダウンロードは
git clone https://github.com/ggml-org/llama.cpp cd llama.cpp
で行う。 - ビルドのコンフィグレーションを行う
cmake -B build -DGGML_CUDA=ON -DCMAKE_CXX_FLAGS="/utf-8 /EHsc" -DCMAKE_C_FLAGS="/utf-8" -DLLAMA_BUILD_BORINGSSL=ON -DLLAMA_BUILD_LIBRESSL=ON -DCMAKE_CUDA_ARCHITECTURES="61;86"
最後の、DCMAKE_CUDA_ARCHITECTURESの61が1080Ti、86が3070用の設定になる。 - ビルドを行う
cmake --build build --config Release - コードページに関するワーニングがでるが無視しても動作した。一部のツールは文字化けするかもしれません。
動作確認
- llama-serverの実行
llama-server -hf unsloth/Qwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_M -ngl 0 -b 512 --flash-attn on --host 0.0.0.0 --port 8080
ファイアーオールが警告が出たらポートを解放する - クライアントからアクセス
http://(llamaのマシンのIP):8080/でアクセス
モデルがQwen3-VL-235B-A22B-Thinking-GGUF:Q5_K_Mで、だいたい、1~2Token/sec、つまり1秒に1文字出力される。何かすると20分ぐらいかかるので、これを高速化できればうれしいという話。
Visual Studioからの起動&コンパイル
- llama.cppをダウンロードした場所にbuildフォルダが作成される。このフォルダをカレントディレクトリとしてVisual Studio(devenv.exe)を起動する。
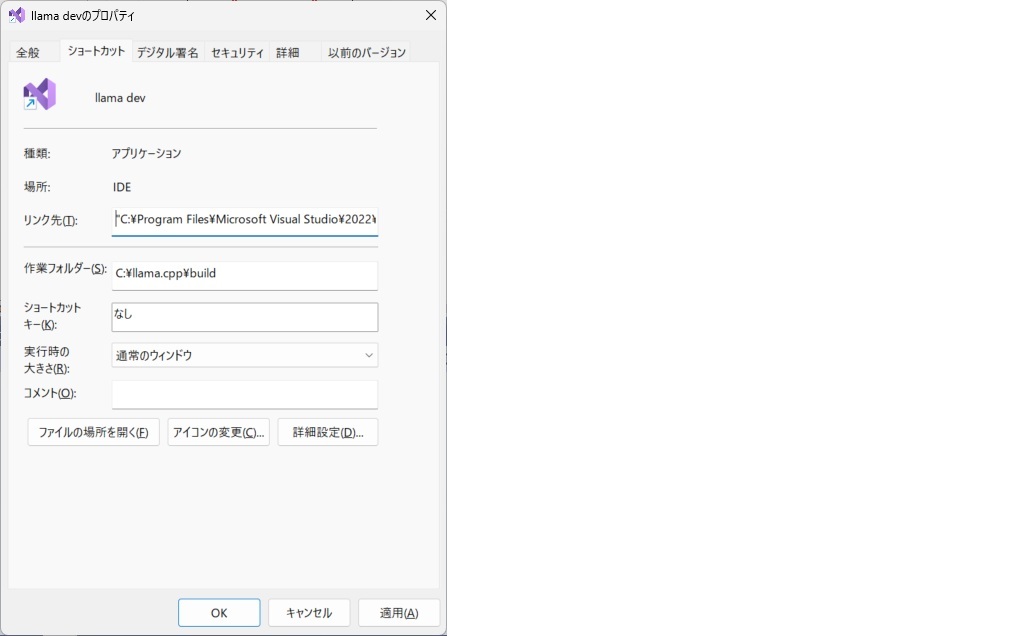
下記の要領でショートカットを作っておくと良い
リンク先:"C:\Program Files\Microsoft Visual Studio\2022\Community\Common7\IDE\devenv.exe" llama.cpp.sln (デフォルトインストール)
作業フォルダ:C:\llama.cpp\build (llama.cppをc:\llama.cppにダウンロードしたと仮定)
- デバックモードとリーリースモードで、リコンパイルを行ってみる。
VTuneのインストール&動作確認
- VTuneをインストール
使っているCPUに対応したバージョンのVTuneをインストールする。 - VTuneは、最新バージョンしかダウンロードできない。2026年2月現在の最新バージョン2025.8.1.7では、Ice Lake以降のCPUしか対応していない。Core i9-10980XEは、Cascade lake(1世代前)なので対応していない。ので、事前にダウンロードしているもの(2023)を利用する。
- 2022では、Windows11 25H2の環境ではインストールに失敗した(厳密にいうと2024のインストール&アンインストール後に行ったのでそのせいでインストールに失敗した可能性もある)。
- 2024では、正常にプロファイルが取れなかった。
- インストール時のオプションで、Visual Studioのツールにチェックが入っていることを確認すること。
- 先に2024をインストールするとアンインストールしても一部ファイルが残っており、2023をインストールしてもショートカットが2024側を指すので起動しない。
C:\Program Files (x86)\Intel\oneAPI\vtune
以下のフォルダをチェックすること。 - 出来れば、古いバージョンから試して不用意にバージョンをあげない方がよい。
- VTuneの起動
インストールが終了すると、Visual Studioのメニューにアイコンがでるのでプロファイルを行える。 - ソースコードを見るには、プロジェクトの設定でデバッグ情報を出力するようにすれば良いが、デバッグモードで行った方が面倒が少ない。この場合、コードが最適かされないのでパフォーマンスが下がるが、概ね、半分ぐらいの速度になる。あまり遅くなっていない。そもそも手動で最適化を行うのでコンパイラの最適化は止めても大丈夫かと思う。手動の最適化が終わった後に最終的にONにすればよい。
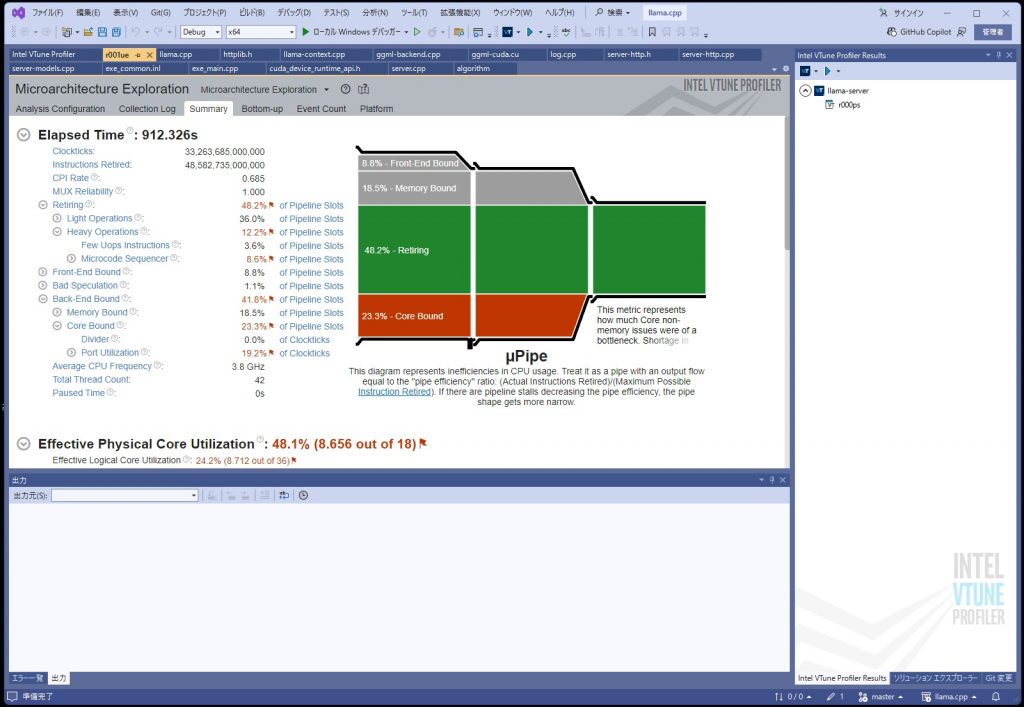
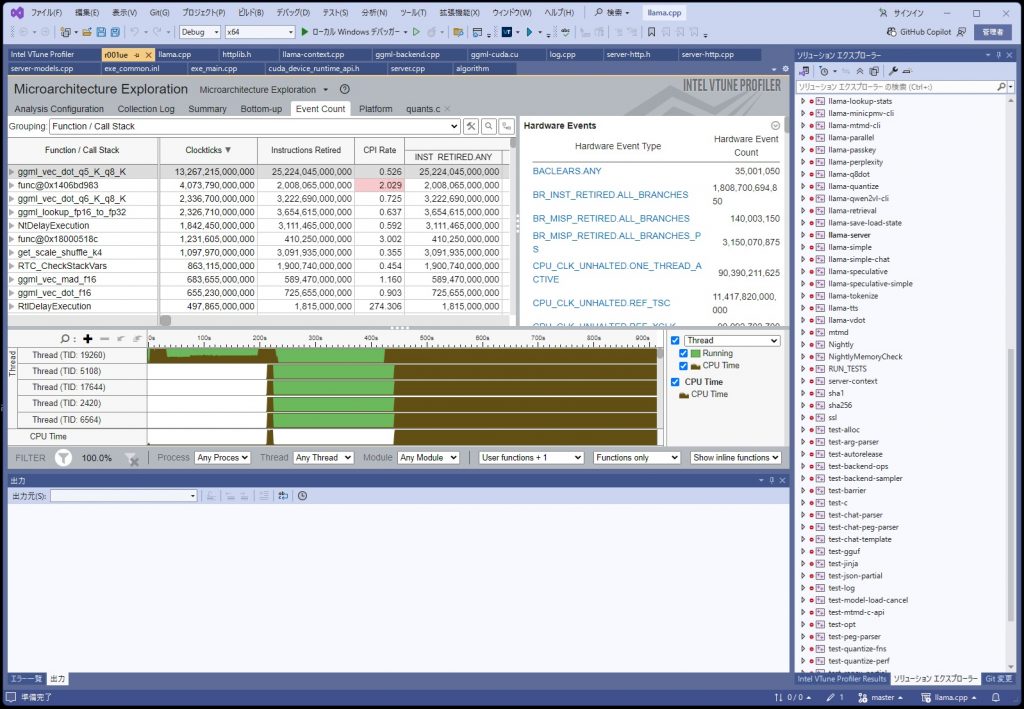
目的の箇所にたどり着けたのでよいが、途中、Bottom-upタブの見方が良く分からないので学習する必要がある。
最も時間がかかっている個所が判明したが、
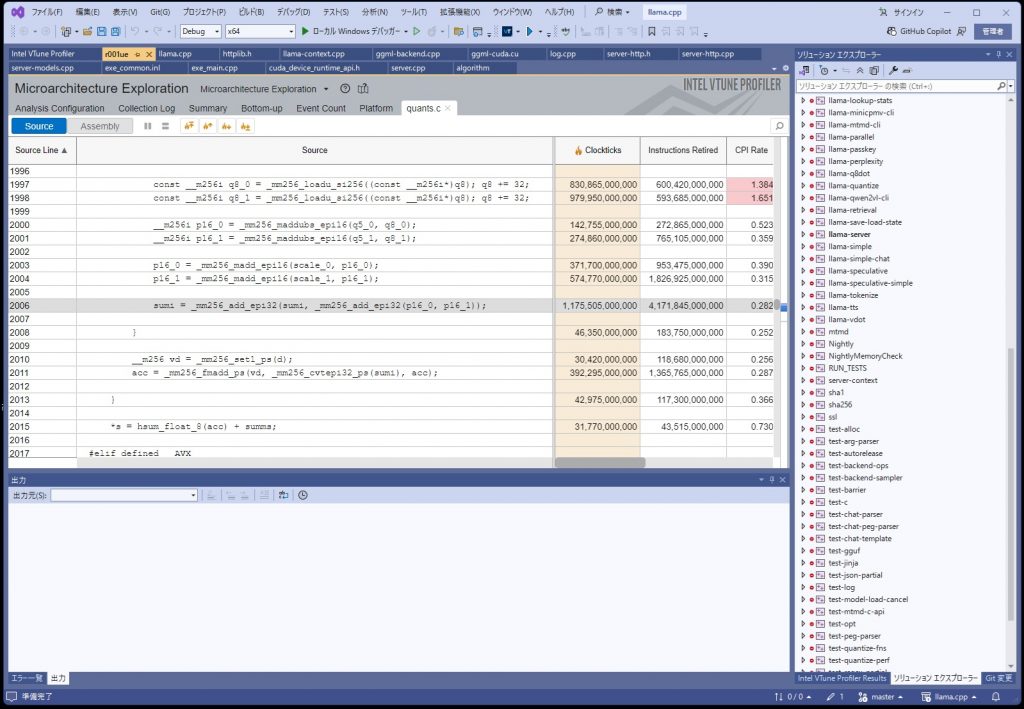
sumi = _mm256_add_epi32(sumi, _mm256_add_epi32(p16_0, p16_1));
どうも、AVX2のコードのようである。まずは、AVX512で動かすにようにして、最適化をかけるようにする。
ボトルネックについて
パット見た感じなので確定的ではないですが、ボトルネックになっているコードは、モデルの重みデータを戻す処理のようである。このモデルデータは、重みが5ビットのものを使っているので内部で8ビットにしているようです。
llama.cppはAVX512を使うといっているがこのデータを戻すところはAVX2のままのようです。
考えてみれば当たり前といえば当たり前なのですが、なんとなく5ビットに圧縮したら展開するのに時間がかかるのではないかと思っていたら、その通りのようでした。この部分の処理時間は全体の約70%ぐらいを占めており、この部分を最適化することは期待がもてる。
もっとも、RAMを大量に積んで利用するモデルを8ビットとかにすればこの部分の処理をカットすることが出来るのでかなり早くなるかと思うが、メモリはこれ以上は積めないので最適化を頑張ろうかと思う。