マルチスレッド&アセンブラプログラミングをしてみる(コラッツ予想のプログラム)
多コアCPUのコアを使い切るにはどうするか?とここ数年考えていたのですが、そういえばコラッツ予想(3n+1問題)を確認するプログラムはちょうどよい例だと思いプログラムを作成してみました。
CollatzAsmについて
せっかくなので64ビットアセンブラで作成し、128ビット(2の128乗)までの数を扱えるようにしました。ちなみに64ビットだと入力が数百億程度(35ビット程度)で内部の計算が桁あふれを起こします。
Visual Studio 2022(C++/Asm)で作成しています。ここからプロジェクトファイル一式をダウンロードできます。
Visual C++ですが32ビットバージョンはインラインアセンブラが使えるので、お手軽にアセンブラを使えたのですが、64ビットになりなぜかインラインアセンブラをサポートしなくなりました。ということで約30年ぶりにアセンブラのソースコードを書きました。
ちなみに、16ビット時代はアセンブラプログラミングの参考書が豊富にあったのですが、64ビットになりあまり見当たらなくなりました。昔はミックスドランゲージといって、Cからアセンブラを呼び出す方法もよく解説をされていたのですが、今では、ここに資料があるくらいで、基本的なことが分かっている人じゃないと意味不明かと思われます。
詳しい解説はご希望があればやりますが、このプロジェクトをサンプルとしてもらえればと思います。
また、このサンプルはC++14のマルチスレッドのサンプルにもなっています。長い間マルチスレッドプログラムと言えばOSのAPIかランタイム関数を使って作っていたのですが、C++14からプログラミング言語にサポートされたということで作成してみました。
実行例は以下のとおりとなります。
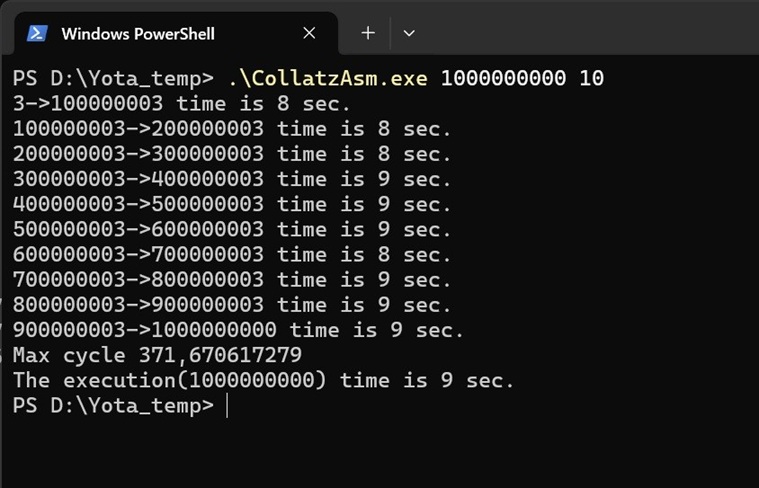
最初の引数で何処までの数を確認するかを入れ、2つ目の数は並列度(スレッド数)になります。
サンプルでは10になっていますが、当然コア数以上の値をいれます。32論理コアに対して100とかにしてもパフォーマンスが上がります(後述)。
CollatzAsmBenchについて
アセンブラでのプログラミングに限った話ではないのですが、プログラムの最適化の過程で試行錯誤を行うことがあります。特にアセンブラでプログラムすると様々な命令を使うことができるのでそのバリエーションが増えるかと思います。
ということで試行錯誤の記録として10個程アセンブラのコードのパフォーマンスを比較するプログラムを書いてみました。
以下、実行結果になります。
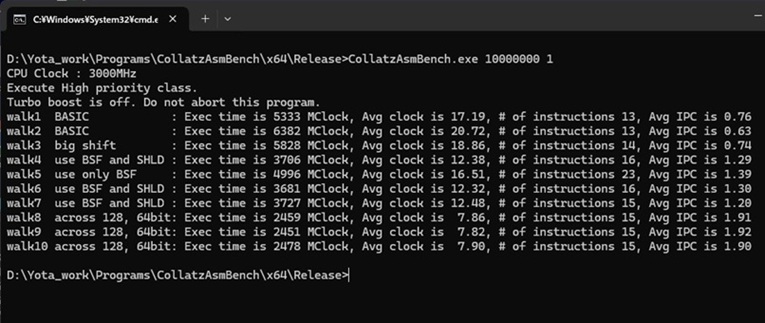
ChatGPTの出力コードとの比較
いわゆるバイブコーディングということで専用のツールも出てきていますが、コラッツ問題を扱うプログラムに関していうと、どこにでもあるのでChatGPTでも簡単なプロンプトでかなりいい感じのコードを出力しています。ということでChatGPTでプログラムを出力させてみました。、実際に試してみたところ可能でしたがあまり速度が変わらなかったので、今回はアセンブラでの出力はしていません。ChatGPTが作成したマルチスレッドのものを掲載します。
私が作ったコードと比較するとマルチスレッドの初期化の取り扱いがうまいです(emplace_backを使っている)。一方で、データ長は64ビット止まりで、並列性も論理コア数に従ってスレッドを作成していますが(hardware_concurrencyメソッドを呼んでコア数を取得している)、このプログラムの場合、各スレッドの実行時間が必ずしも同じではないので、スレッド数をより多くして各スレッドのタスクを細かくした方が、実行時間のばらつきの減少が期待できます。一方で、一般論になるのですが、論理コア数以上のスレッドを実行させると各スレッドがCPUのリソースを食い合いすることになるので、実行スレッド数を論理コア数に合わせるのも一つの手になります。
今回はアセンブラでは比較をしませんでしたが、CやC++のコードを単純にアセンブラにしてもあまり早くならないということもあります。一方で128ビットのような桁数の多い計算をさせる場合、アセンブラには桁あふれを処理する命令があり、CやC++で組むよりはるかに効率的なプログラムが記述できます。機会があればChatGPTでアセンブラプログラムの最適化を行いたいですが、↑の例にあるようにAIに任せるより、自分で工夫をした方が手っ取り早い面があります。もちろんですがアイデア出しをAIに頼ることもできますので、こういうことではあまりAIと人間の比較は意味がない(人間からしたらAIも利用する)ということになりますが、2025年9月現在、このあたりのチューニングはまだ人間の方に一日の長があるかと思います。(追記)この記事の公開後、1週間でClaudebotと名乗るロボットからZipファイルがダウンロードされたのでひょっとしたらClaudeにコードがパクられるかもしれません。
最後に実行結果を
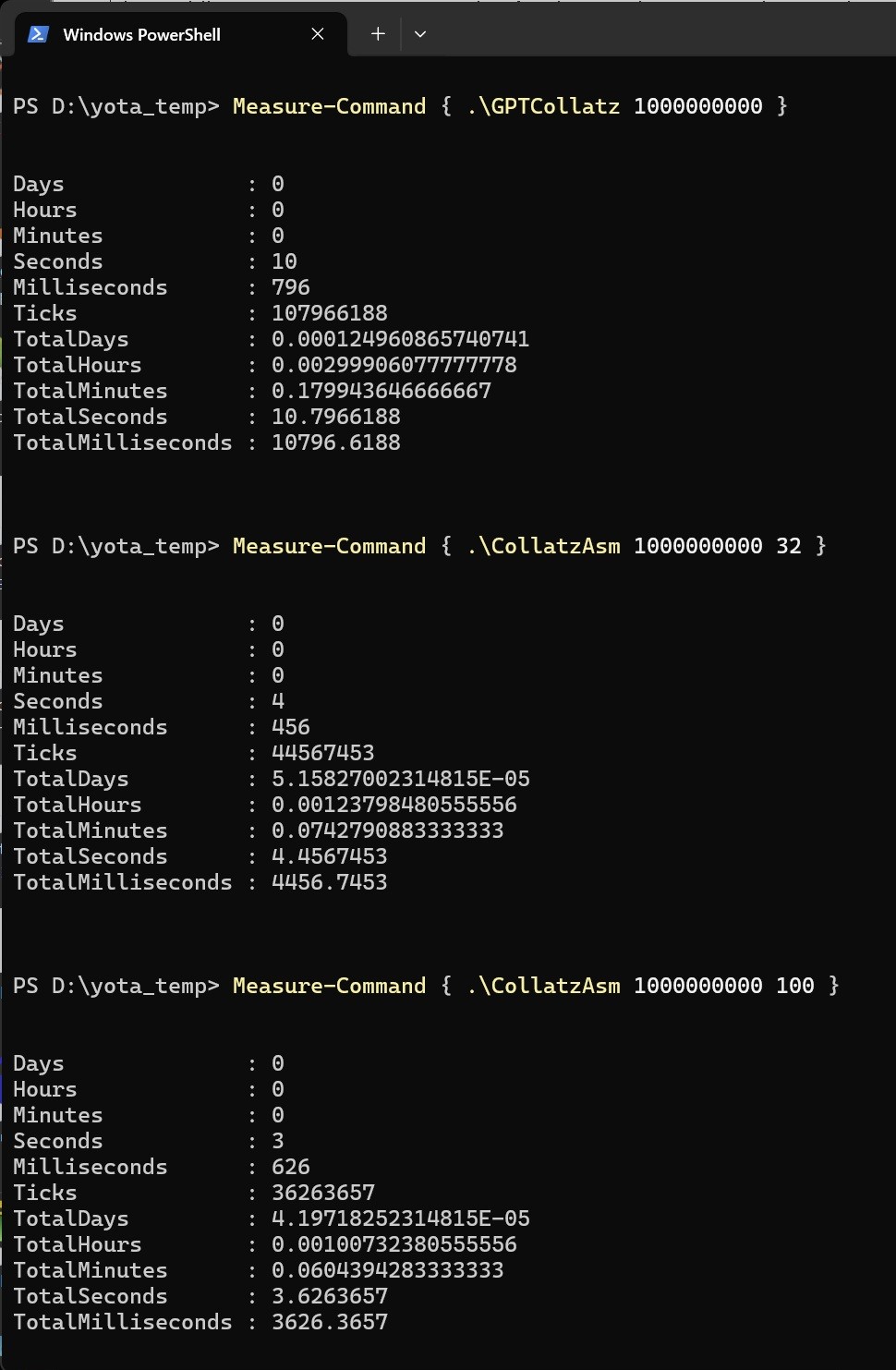
ということで、倍以上のパフォーマンスを示しています。逆にいうと倍程度にしかならないのですが、ある処理時間が半分になるということは2020年代のCPUの進化でいうとほぼ10年に相当します(この場合シングルスレッド性能の比較になる)。つまり上手くアセンブラでプログラムを書き直すことができればCPUの進化を10年先取りできるとも言えます。CPUのシングルスレッド性能の向上が顕著だった90年代ですと概ね1,2年でパフォーマンスが倍になっていました。
余談ですが、アセンブラでのプログラミングは8ビットや16ビットの時代は割と一般的でした。90年代以降ではCPU自体の進化が早かった為、アセンブラでのプログラミングがエンコードなど、いわゆるSIMD命令を使うためとか、ニッチになった感がありました。CPUのシングルスレッド性の向上が見込めなくなった昨今、アセンブラでのプログラミングが見直されるかもしれません。
話を戻すと、コラッツ予想の確認プログラムの場合、スレッド数を100にしても性能が伸びていることを確認できます。これは、前述のとおり値により処理ステップにばらつきがあるためで、区間を細かくした方が(スレッド数を多くし多方が)、CPUから見た場合のトータル処理時間が平均化される為です。