ダジャレクラウドのリリース
以前、ブログに書いていたダジャレクラウドですが、晴れてリリースとなりました。遊び方ですが、『ダジャレ・リサーチ』というテキストボックスにキーワードを入力し、検索ボタンをクリックするという至ってシンプルなものになります。
ちなみに最近私が面白いと思ったものは『オリンパス』で検索したものです(まぁ少々ブラックですが・・・)。
ソフトウェア開発の常なのですが、このプロジェクトも遅延しましたが何とか無事にお披露目できるようになりました。
あまり赤裸々に書くのも如何なものと思われるかと思いますが、こういった経験は私自身も肥やしになるのと、あまり外には聞こえてこないもので興味深いと思いますので、適当にフィクションを入れつつ記事を書いてみます。ので以下はフィクションと思って頂ければと思います。
■ プロジェクトの目標がはっきりしているか?ぶれないか?
もともとHack4JPという震災復興プロジェクトの1つとして立ち上がりましたが、『だじゃれ』と『震災復興』というあまりにもかけ離れたお題に対して一部のメンバーが動機付けに苦労し余計な時間を費やした点が上げられます。
つまり、プロジェクトだじゃれという不謹慎なものに対して負い目を感じ、それに対して大義名分をつけようとして『開発を行う』というエンジニアの本分を忘れてしまい結局開発に手が付かなかった点があります。
結局は、『ダジャレで被災者を応援しよう』という当初の目標に落ち着き混乱が収拾されました。
■ボランティアに対するスタンスの違い
私はこういうボランティアは始めてなのですが、メンバー間のボランティアに対する認識の違いがありました。
私の中では、参加条件が『プロが無償でする』であり、その方が『出来る範囲で出来ることをする』という認識でいました。
『プロが無償でする』というのはどういうことかと申しますと速い話がボランティア(タダ)といってもいい加減な仕事をしてはいけないということで、例えますと英語ができない人が通訳のボランティアをやっては逆に迷惑でしょう。ということです。
つまりソフトウェア開発プロジェクトなら開発ができる人が開発を行うということなります。
当たり前ですが、どのようなソフトウェア開発プロジェクトも開発者だけ回りません。リーダーやプランナーの方とう様々な役割をもった方も必要です。チームとして活動する場合はそういったリーダーやプランナーとして仕事ができる人も参加する必要があるでしょう。
プロジェクトの混乱の1つにこのスタンスの違いがありました。つまり、無償で作業をするという認識は一致していたかと思いますが、「プロ」の部分が抜けておりました。先ほどの英語の例でいいますと英語がしゃべれないけど通訳のボランティアをするといった具合です。もっとも明らかにしゃべれないなのらヤメトケで済みますが、微妙な場合は線引きが難しくこれが混乱の元になりました。
『できるかどうか解らないがやってみる』というのはありかと思いますが、その場合は周りに迷惑にならない程度に『やっぱりできませんでした』とか『ここまでならできました』とかの報告が欲しいものです。
ボランティアに限った話ではないですが、厄介なのが充分な能力をもっていないが自分はできると思っていたり、『出来ません』と言えずに引くに引けないようになってプロジェクトが停滞しました。
この点のもう1つの問題が、メンバーの意識として『出来る事をする』ではなく『したい事をする→出来ないことをやろうとする』になってしまう点です。これが復興支援という大義名分と融合して混乱に拍車をかけた部分があります。当たり前ですが、ほとんどの日本人(世界の人)が東北の方の1日でも速い復興を願っています。前項とも絡んでくるのですがその思いが空回りして、したい事をプロジェクトとして実行させようとし結果として、出来ないことをやろうとすることになっていました。
■ボランティアに対するスタンスの違いとプロジェクト運営の経験不足
そもそも論としてボランティアだからモノを完成させる必要はないという認識の方もいらっしゃいました。こういう考え方自体は悪くないかと思いますが、少なくとも依頼者は完成させて欲しいと思っていますし、また、メンバー内にも完成させたいと思っている方も当然居ました。この場合は明らかに完成に向けて作業を行う必要があるかと思いますが、そういった中でご自身の意見を優先される方がいらっしゃいました。
個人の意見がプロジェクト運営上妨げになるという場合、その点については当然調整を行う必要があるでしょう。つまりある部品の開発者であったが興味を失ったので開発はもう終わりにしたいと思った場合、別の開発者に任せるようにする必要があるでしょう(本来ならある程度完成させてから抜けるのが筋だと思いますが・・・)。それをプロジェクトとして完成させる必要がないとされると周りの者が迷惑をこうむります。
■文化の違う方とのコミュニケーション
立場の違う人達が集まると波風が発生するもので、上記の認識の違いやら、果ては言葉遣いや段取り等の違いから波風が立ちました。
このプロジェクトですが見た目が簡単で面白そうなのでエンジニアでない方も入ってこられました。
それ自体は悪くはないですが、例えば、システム開発で発注者の立場の人と受注者の立場の人がボランティアで一緒になるとほぼ立場が逆転します。なぜなら発注者というのはお金という力を使って受注者をある意味支配していますが、ボランティアベースになるとお金という力がなくなるので、別の何かで開発者の方と協力しあわなければなりません。
こういったところでコミュニケーション不足が一部にありメンバーの不満が高まったこともありました。
この点については幸いにも粘り強く話しをしたら誤解であったことが解り、開発者でない方のプロジェクトに対する貢献方法(広報活動だったりプロジェクトの企画だったり)を考えることにより作業が進行できたので、1つ収穫になりました。
とまぁ色々問題が発生しましたが齢40を過ぎていい社会勉強になりました。
2011-11-11 | コメント:0件
プログラマ35歳定年説を検証する part1 - TopCoder
気が付けばまたもやブログの更新がおろそかになっていたので近況がてら更新します。ちなみに、スマートフォンはもういやだ!と思っていたのですが、業務命令でiPhone4S(ア・イ・フ・ォ・~・ン)を予約したのですが1ヶ月待ちとのことで今しばらくはX01Tとのお付き合いになります。まぁ手に入ったらまたレポートなんぞをしてみます。
ADP1周年記念やSQLのパフォーマンスについてのまとめページが進んでいませんし、ダジャレクラウドとか地味にその他に書くことがあるのですが、最近ちょっと関心を持った話題を書きます。
今から20年以上前にまことしやかに囁かれた『プログラマ35歳定年説』という仮説がありまして、まぁ『35歳ぐらいになったらプログラマとしては役に立たなくなる』という感じで使われたりします。まぁ一種の都市伝説のようなものですが、実際に信じている人も多いようで
私は今年で40歳を超えるのですが、いまだに開発を行っていますし何よりこのブログが『俺は使える事を』証明しているとも思わなくもないですが、もっと客観的に証明する手段として、TopCoderというものがあると思いましたのでそのお話でもしてみます。
TopCoderというのは、プログラミングコンテストの一種で、競技プログラミングとも呼ばれており、制限時間内(75分)にお題にそったプログラムを組むというものです。
問題は、簡単・普通・難しいと3つ出題され、それぞれ難易度とプログラミング時間によってポイントが付き、そのポイントを競うというものです。
単純にプログラミングをして終了ではなく、プログラミング後、他のメンバーが作成したプログラムを参照できバグを発見したら(バグを現出させるテストケースを与えれば)、別途ポイントがもらえます(チャレンジという)。
そのようにやってポイントを稼ぐと、レーティング(通算ポイントのようなもの)が貰え、そのレーティングによって順位付けがされるというものです。
私の現在のレーティングは1391になりますが、これは9138人中の2047位(全世界)、766人中の141位(日本)らしいです。
この順位で私が使えることが証明されたかどうかは実はいまいちなのですが、私より順位が下の人には某一流大学の人たちもいますので、そういう意味では『まだまだ若いもんには負けていない』ということはいえるかと思います。もっとも私より上位にも某一流大学の方が居るので一概に某大学生に勝ったとはいえません。
レーティングが上位になると『レッドコーダー』と呼ばれるようになります。なぜレッドかと言いますとレーティングによってIDが上から、レッド、イエロー、ブルー、グリーン、グレイで色分けされる関係でそう呼ばれるようです。私の現在の色はブルーになります。参加しだして間が無いのでなれていない面もありますので、精進を重ねレッドコーダーになれば、晴れて私も使えるプログラマということが証明されるかと思います。
75分という極めて短い時間でプログラムを作成するので本当の実力の一部分しか計測できないでしょうが、問題自体は非常に良く出来ているとも思いますし、何より自分の実力が客観的に判るので腕に覚えのあるITエンジニアの方は是非挑戦してみては如何でしょうか?
2011-11-07 | コメント:0件
LGA2011とSandy Bridge-E
最近、ブログの更新が滞っておりますので、近況報告がてら更新します。(ちなみに、国内旅行取扱管理者が受かったのでその記事でもと思ったのですがそういえば受験した記事を書いていなかったのでまたの機会にします。)
世の中不景気と円高が続きますが、あいも変わらずコンピュータ関係は順調に進歩を遂げており、私もニュースをみながら「次世代の私の使用機はどうしようか・・・」と日々ニュースをチェックしてます。
ちなみにちょうど1年程前にこの記事で、『CPUコア数が6(スレッド数12)で、搭載メモリが24GB』とか言っていましたが、最近、マザーボードが発表になりましたX79というチップセットではDIMMスロットが8個ある製品も発売されるらしく、最近では1枚辺り8GBの容量をもつDIMMが発売になりそれも一部では1万円を切る値段になったので、64GBのメインメモリが10万円を切る値段で手に入るということになるようです。
X79はソケットがLGA2011で対応するCPUはSandy Bridge-Eらしいですが、このCPUは8コア(16スレッド)のものもあるようです。
つまり、2011年末~2012年の頭頃に
CPU:8コア(16スレッド)
メモリ:64GB
というマシンが30万円も出せば手に入るということになるかもしれません。
ちなみに、現在私が使っているマシンですが、
CPU:4コア(4スレッド、HT OFF)
メモリ:12GB
になっています。
CPUはCore i7-920で、Hyper-ThreadingをONにすれば8スレッドになるのですが、OFFで使用しています。
私の使用方法では、8スレッドを使うことはほぼなく、無駄に電力を使うのもなんなので早々にHTをOFFにしました。ちなみにBIOSでは使用するコア数も変えられたので2コアとかにしてみたのですが消費電力的にはあまり効果はなかったので、そこは一応ということで4コアで使っています。
ちなみに、ADP Ver 0.74でマルチスレッド機能(pipe述語)を搭載し、テスト中にCPU使用率が100%になり、『やっと使い切った』と喜んでいました。
またメモリも24GB搭載できるのですが、12GBで特に不満を感じていません。空き容量が7GBでキャッシュが3GBとか言われるとさすがに増設する気になれませんな・・・・
とまぁこんな感じでまったく気合が入っていませんが、まぁ来年あたりまだ円高が続くようでしたら手ごろな価格で高性能マシンが組めるので狙ってみたいです。
2011-10-28 | コメント:0件
[ADP開発日誌 ]Ver 0.76 リリース もろもろ
ブログの方ですが、一周年記念記事やSQLのパフォーマンスの記事が、遅々としてはかどっていませんが、ADPのリリースがありましたので更新してみます。今回は、幾つかのバグフィックスとソート述語、pow(べき乗)述語を追加しています。
以前の記事で、マルチスレッドの充実やらリソース開放機能の追加などを予定していましたが、地味な改修にとどまっています。が方々でADPを使おうと画策しております。
まず、SQLのパフォーマンスの記事はADPを使って実験しています。ちなみにソート述語はその関連で追加しています。
また、以前に紹介しましただじゃれくらうどですが、これのWEB-APIをADPで作成したりしております。現在リリースに向けて作業中だったりします。
べき乗の追加はなんだと思われるかもしれません。最近知ったのですが、Googleさんの方でCode Jamという、プログラミングコンテストをやっておられるのですが、コンテストで使用するプログラミング言語にある程度自由度があり、であればADPでやりましょうということで、次の目標を『Code JamをADPで参加する』ということにしました。
その関連で少しずつですが、Code Jamにも耐えられるような言語ということで改修しています。
ちなみにですが、今年はC++で参加しました。
2011-10-11 | コメント:0件
JOINのパフォーマンスについての考察2(リレーションとの関係2)
ちょっと間があきましたが、JOINのパフォーマンス関連の続きになります。
前回、JOINのパフォーマンスについての考察(リレーションとの関係)でJOINを行った結果、データが非正規化するとその非正規化の度合いによってパフォーマンスが下がるという話をしました。
前回の記事では、1対nの結合ではJOINを外す(単純なSQLに分割してホスト言語側で結合させる)ということで、定性的な話しかしていませんでしたが、幾つか実験を通して、もう少し定量的な話をしてみます。
『たかがJOINで、なぜこねくり回すのか?』と思われるかもしれませんが、こういう実験&考察というのは意外に行われていないかと思います。私自身定性的なことは理解していたつもりでしたが、実際に実験を行うと色々と発見がありますので、記事にしてみます。
大切なことは解った気になることではなく真実を追究する姿勢で、先入観を持たずにきちんと実験を行いパフォーマンスに対する感性をみがくことは大切かと思います。
今回、調査するアルゴリズムについて
今まで何回か実験してきましたが、実験で使用してきたアルゴリズムについて説明します。1.SQLでJOINを行う。
SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price INNER JOIN Company ON (Price.CODE = Company.CODE)という風にSQLでJOINを行います。普通の処理になります。
2.ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,RDATE,OPEN,CLOSE FROM Price (2) SELECT NAME FROM Company WHERE CODE = ?
(1)のSQLを実行して結果を取得しますが、NAMEについては(2)のように再度SQLを発行します。
ここで、単純にPriceテーブルの全ての行に対して(2)SQLを発行するのではなく同じ結果をキャッシュして同じCODEの場合はキャッシュからデータを取得するようにします。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,NAME FROM Company (2) SELECT CODE,RDATE,OPEN,CLOSE FROM Price
(2)のPriceテーブルからのデータの取得に先立ちまして、(1)でComapnyテーブルから全てのデータを取得しておきます。
多くのDBMSで行っているハッシュ結合を真似ています。
1対nの2つのテーブルのJOINにおけるパフォーマンスモデル式
続いて、各アルゴリズムのパフォーマンス(実行時間)のモデル式を示します。ここで、
n : Priceテーブルの行数
m : Companyテーブルの行数
c10,c10,c20,c21,c22,c23,c30,c31,c32 : 比例定数
になります。
1.SQLでJOINを行う
1.のパフォーマンスのモデル式は以下のようになります。c11 * n + c10
Priceテーブルの行数に比例した時間で結果を取得できます。ここでc11は比例定数であり、C10はオーバーヘッドにあたります。
2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
2.のパフォーマンスのモデル式は以下のようになります。c21 * n + c22 * m + c20
Priceテーブルの行数に比例した時間と、Companyテーブルの行数に比例した時間およびオーバーヘッドの合計になります。
『c22 * m は c22 * n * m になるのでは?』と思われるかと思いますが、キャッシュのおかげでこのようになります。
また、「1.SQLでJOINを行う」と比べますと、c22 * m と余計な項が付いていますので、
SQLでJOINした方が速い
と早合点される方がいらっしゃるかと思いますが、JOINのパフォーマンスについての考察(リレーションとの関係)で述べたことは、c11とc22の定数値の差異となって現れてきます。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
3.のパフォーマンスのモデル式は以下のようになります。c31 * n + c32 * m + c30
面白いことですが、形式的には「2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)」と同じになります。
ちなみに、[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011 にあります、「SQLの発行回数のオーバヘッドはどこにいったんや?」と思われるかもしれませんが、それはc32とc22の差異に出てくるということになります。
実験と結果
今回の実験では、nの値を変えながら実行時間を計測することにより、各モデル式の定数を求めます。求めるといってもグラフを書いて状況を観測します。厳密には回帰分析とかを行うことになるでしょうが、グラフが直線になることと、nが増えたときの傾向をつかめればよろしいかと思います。アルゴリズムの教科書ではオーダーという概念があり、オーダーでは定数を求めることは無意味とされています。つまり上記のアルゴリズムは論理的には違いがなくどれも一緒ということになります。
つまり、2倍や3倍の差はあまり意味がないということですが、もっとも、実際の現場ではこのような差にも敏感になるので、きちんと計測して値を出すことになります。
また、今回はmは固定(約2000)で行っています。mが変動したときにどう変わるのかも興味深いですが今回は、m << n ということで結果にはあまり影響しません。
先ずは、結果から、
| 0行 | 373,740行 | 1,172,191行 | 2,002,749行 | 4,671,568行 | |
|---|---|---|---|---|---|
| 1.SQLでJOIN | 718 | 10,015 | 29,938 | 52,329 | 119,192 |
| 2.キャッシュ付のネステッドループJOINを行う | 671 | 10,469 | 30,172 | 49,814 | 116,770 |
| 3.ハッシュJOINを行う | 2,828 | 11,422 | 29,797 | 49,845 | 110,988 |
つづいて、グラフを以下に示します。
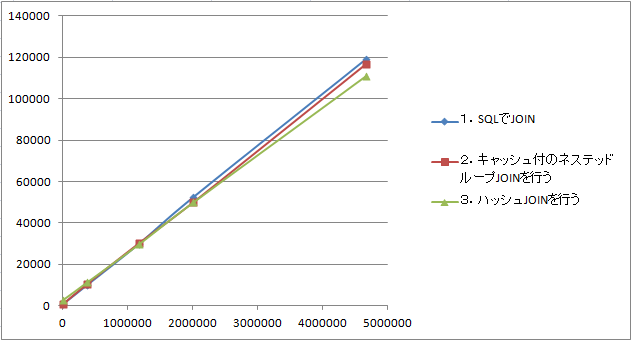
縦軸が時間で、横軸が行数(n)になります。グラフをみますとPriceテーブルの行数(n)が増えると「1.SQLでJOIN」より、「2.キャッシュ付のネステッドループJOINを行う」や「3.ハッシュJOINを行う」の方が速くなっていくことが解るかと思います。
パフォーマンスにシビアになる時は、往々にしてnの行数が増えるような場合にあたるということになります。その場合は1より2や3を選択した方がよいということになります。
もっともグラフを見て解るとおり差はあまりないので、通常はやはり普通にSQLでJOINを行い、パフォーマンスを稼ぎたくなったら2や3を検討するということになるでしょう。
2011-09-29 | コメント:0件