[ADP開発日誌 ]Ver 0.75 リリース バグフィックス
ブログの方ですが、一周年記念記事の追加やSQLのパフォーマンスの記事等ちょっととっちらかった感がありますが、ADPのVer 0.75をリリースします。基本的にバグフィックスになります。
・insert / update / delete でメモリリークのバグフィックス
・組込み述語(_table_quote)を削除し、組込み述語(_db_quote / _db_default_quote)を追加した。
SQLのパフォーマンスの記事のアップに際して環境を整えましたが、その際にデータのコピーをADPでやらせてみたところバグが発覚したので修正しました。
またSQLServerからMySQLにデータをコピーするに際してクオート文字の指定が_table_quoteだと不完全なので整理しました。
ちなみに、insertの性能ですが、悪いです。
MySQLやSQLServer2008以降では、多数の行をインサートするために、マルチプルインサート、Oracleではマルチテーブルインサートが使えるので、検討してみたい(専用の述語の追加になるか?)。
2011-09-13 | コメント:0件
JOINのパフォーマンスについての考察(リレーションとの関係)
コメントを頂いたのですが、ちょっと返し方が悪かったのか音信普通になりましたので、改めてJOINのパフォーマンスについて考察してみます。1対n結合の場合、JOINとは正規化データから非正規化データを作り出す操作になる
RDBのテーブルは、きちんと設計されていれば、正規化されています。つまりデータに重複がなく容量の面で効率的になっています。ここで正規化データとはあくまでもRDBにとって効率的というだけでそれ以上のものではありません。一方で人間が理解しやすいデータ形式は必ずしも正規化データというわけではなく、往々にして非正規化されたデータの場合があります。JOINを行うということは正規化されたデータを非正規化データに戻す操作ということに相当します。つまり、効率のよいデータから人間にとって理解しやすいデータ形式に戻す操作になります。JOINは正規化されたデータから非正規化という効率の悪いデータ形式に変換する操作になります。
SQLでJOINを行い、その結果を取得するということは何らかの非効率な行為が行われているということがわかるかと思います。
RDBのコピーを行おうと考えた場合、わざわざJOINなどせずに、テーブル毎にコピーを行おうとするでしょう。RDBからデータを取り出すとき同様に正規化された単位でデータを取得した方が有利な場合があるということは理解できるかと思います。
RDBでは正規化データから非正規化データを作り出す方が非正規化データから正規化データを取り出すより効率的
先ほど、JOINは非効率といいましたが、なぜRDBでは効率の悪いJOINが行われるのでしょうか?理由は簡単で、RDBの理論では、
・非正規データ から 正規データ を作る
操作より
・正規データ から 非正規データ を作る
操作の方が効率的と考えられているからです。非正規データから正規データを得るにはグループ化を行います。つまりGROUP BYを行う必要がありますがこれはつまりソートを行った上に重複したデータを圧縮することに相当します。一方でJOINはデータの検索に相当します。例外はありますが検索の方がソート&圧縮より効率的なのは理解できるでしょう。
さらに、正規化データは非正規化データより更新が容易ということもあります。
つまり、関係データベースの世界では正規化されたデータは非正規化されたデータより効率がよいと考えられています。ちなみに、この認識が間違って拡大解釈され、『SQLは効率がよい』という誤解が生まれたと想像されます。
1対nの結合で一方のレコードサイズが小さいとき、2つのテーブル間の単純なJOINは効率的、だがデータの出力が非効率
FROM table_a INNOR JOIN table_b ON (table_a.table_b_ID = table_b.ID)のSQLがあるときに、
table_aがマスターを参照するテーブルで、table_bがマスターテーブルと仮定します。つまりtalbe_aとtable_bが1対nで結合されており、さらにtable_bがメモリに入る場合、JOIN自体のコストはほとんどかかりません。
2011年現在、サーバーに搭載されるメモリ容量が数十GBのオーダーになります。一方でマスターテーブルの容量は多く見積もっても数百万件のオーダーになり、各データを多く見積もって1KBとしてもマスターテーブルのデータ容量は数GBのオーダーとなります。実際にはJOINに必要なデータのみメモリにおいた場合、必要なデータは1桁も2桁も減ることになります。結果として1対nの結合ではほどんどの場合、マスターテーブル側はメモリに乗ることになり、JOINにおいてマスター表の操作は高速に行えます。
しかし、1対nの結合では、結果を取得する場合に、結果データが非正規になる為に非効率になります。
この場合、JOINを分割して、呼び出し言語側でJOINした方が理論的には効率的になります。実際どこまで効率的になるかは分割による複数回のSQLの呼び出しのオーバヘッドと繰り返しデータの量に左右されます。
1対1結合の場合は、JOINは出力も含めて効率的になる
1対1結合の場合は、結果データも正規化しているのでJOINは効率的になります。JOIN自体が効率的に行えるかどうかはデータ量やデータ(または結合キーのインデックス)が整列されているかどうかによります。結論
以上のように、扱うデータの性質によってSQLでJOINさせる方がよい場合とSQLではJOINさせない場合の方が理論的に速くなる例を示しました。結合の種類が1対nの場合、JOINを行うとデータ非正規化し、容量が増えるので出来るだけJOINを遅らせるテクニックが有効になる場合があります。
実際にどのような状況のときにJOINを遅らせたほうがよいかですが、マシンのスペック、ネットワークの環境等に依存しますが、傾向として行数が増えた場合や1対nのJOINの数が増えるとJOINを遅らせる方が有利になります。このような場合でパフォーマンスに問題が発生した場合にJOINを遅らせるテクニックを検討されると上手くいく可能性が高まります。
一方で、結合の種類が1対1の場合、データは非正規化しないので、SQLの発行の段階でJOINを行えば有利になります(JOIN自体のコストはまた別の話になります)。
2011-09-06 | コメント:0件
対峙
一周年記念記事とかLLの感想とか書くネタはあるのですが、某読者より『最近、猫感が足りないですね。』とご指摘を受けたので久しぶりの猫ネタです。うちには、ミミとチャチャで2匹の猫が居るのですが、この2匹は非常に仲が悪く目を離すと直ぐに喧嘩をします。
不穏な空気が出始めます。

ちょっかいを出し始めるのはチャチャ(茶色)の方になります。

さしずめ、川中島で対峙する、武田信玄と上杉謙信のようです。

2011-08-31 | コメント:0件
通訳案内士試験
先週のLL Planetsに引き続き、今週末は通訳案内士の試験で、来週末、さ来週末とこのところ予定が目白押しですが、去年に引き続き、28日に通訳案内士の一次試験に挑戦しました(このブログを書いているのは30日)。
今年は、昨年受かった地理と一般常識が免除になり、英語と歴史を受験しました。
通訳案内士の試験ですが、地理、歴史、一般常識がマークシートで問題用紙を持ち帰ることができます。
地理、歴史、一般常識は平均点を取ればよいので甘く考えていたのですが、今年の歴史はだいぶレベルが高く私の得点も微妙で、『また来年』ということになりそうです。
一方で、英語の試験ですが、記述式で試験終了後問題用紙も回収されますのではっきりしたことはいえませんが結構出来が良かったです。
もっとも、問題が去年と比べて易しくなったようで、例えば英作文の場合、『バレンタインデーとは何か?』を80ワード程度の英語で書かせる問題だったのですが、今年は『女性専用車を3,4行(恐らく30~40ワード程度)で説明せよ』、『こいのぼりを3,4行で説明せよ』とかだいぶ問題の難易度が下がったかと思います。80ワードでの作文と40ワード程度×2だと、当然80ワードで書く方が深く説明しなければならないので難易度が高いかと思います。もっとも簡潔に必要事項をまとめるということであれば逆に難易度が高くなりますが問題文からはそう深堀も出来ないかと思うので簡単になったかと思われます。
英語の合格基準は『平均点を60点とした場合に70点を合格とする』とよく解らない基準で、平均点より10点以上上回ると合格というイメージのようなので、私の英語力を鑑みるとこちらも通るかどうかは微妙です。しかし、2年も英語の勉強を続けているとさすがにそれなりに上達するもので、来年は合格に手が届きそうです。と手ごたえを感じただけでも良かったです。
場合によっては歴史が落ちて、英語が通るということもありえるのですが、そうなると歴史の方をだいぶ軽視し英語の勉強ばかりをしていたので少し悔いが残ります。
2011-08-30 | コメント:0件
[ADP開発日誌]0.74リリース マルチスレッド化の第一歩 & LLPlanets発表用リリース
ADP公開一周年記念記事がまだ途中ですが、 Ver0.74のリリースを行います。
Ver0.74は、Accessでの整数のインサート時のエラーの改修と、pipe述語の実装があります。
pipe述語というのは、以前話に出ました、マルチスレッド機能の1つでパイプライン処理を実現する述語になります。
ちなみに、本リリースにに基づき、LLPlanetsのライトニングトークで発表を行います。私を見かけた人は『ブログ見てます』と声を掛けていただければうれしかったりします。
では、pipe述語の使用例を見てみましょう。何回かやっていて最近ホットなSQLのパフォーマンスについての例になります。
関連記事1:[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011
関連記事2:SQLの実行パフォーマンスについて 2010
実験環境
JOINのパフォーマンス実験環境はこちらに記述しています。実験1 素直にSQL側でjoinをさせたものを実行(再掲)
例により、SQLで素直にjoinさせてみます。以下のようなコードになります。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).csv.prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験1と同じです。
実行時間も同じで、約119秒です。
実験2 ADP側でjoin(ネステッドループ&キャッシュ)
続いて、ネステッドループjoinをADPのキャッシュ機能を使って高速化をはかります。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験2-Bと同じコードになります。
実行時間ですが、約117秒となりました。実験1と比べて約1.6%程速くなっています。
実験3 ADP側でjoin(事前にマップ作成)
3つ目は、ADPでも事前にマップを作成し、joinを行うことができます。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011の実験3と同じコードです。
実行時間ですが、約111秒で実験1より7%ほど速くなっていることが解ります。
続いて、pipe述語を使って並行処理をさせてみます。
実験1-P 素直にSQL側でjoinをさせたものをpipe実行
実験1のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,$str = "SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price "
"INNER JOIN Company ON (Price.CODE = Company.CODE)"
,sql@($db,$str,[]).pipe.csv.prtn,next;
実験1のコードとの違いは4行目の,sql@($db,$str,[]).pipe.csv.prtn,next;
のpipeという記述で、これがpipe述語になります。pipe述語で区切られたコードは並行で処理を行います。
つまり
,sql@($db,$str,[])
の部分(バックトラックの実行)と
.csv.prtn,next;
の部分は並行で動作します。
sqlの部分は、.csv.prtn,nextの実行中にバックトラックを行います。
next述語で、pipeまで戻りますと、sqlの実行を待ち(同期)データを受け取ります。
ややこしいかも知れませんが、図で示すとよくわかるかと思います。
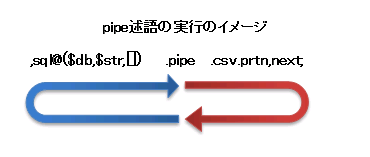
図で、青の矢印の部分と赤の矢印の部分がそれぞれ別のスレッドになっており平行で動作しています。
pipe述語が無い場合の動作イメージは以下のとおりです。

比較してみますと分かりますが、sql述語~next述語まででループがありますが、それを2つに分けて実行するイメージになります。
UnixのシェルやWindowsのコマンドプロンプトで、|(パイプ)を使ってコマンドをつなげることがありますが、pipe述語の実行イメージはこれと同様になります。
シェルのパイプ(|)は20年以上前からあり、お手軽にマルチタスク処理を実現できるのですがプログラム言語レベルで使えるものがなく、マルチスレッドプログラムとなるとなぜかややこしくなります。
ADPではお手軽にマルチスレッドプログラムを体験して頂くため、その一つとしてパイプを実装しました。
実行時間は、約108秒で、約9%速くなっています。少しですが実験3よりも速くなっていることが解ります。
実験2-P ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行
続いて、実験2のコードにpipe述語を挿入しています。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,csv($rec,$name).prtn,next;
実行時間は、約89秒で実験2と比べて約24%速くなっています。
興味深いのは実験1-Pよりも速度向上が大きいです。pipe述語は半分に分割してそれぞれ実行するという方式をとっていますが、当然ですが常に半分になるとは限りません。上手く半分に分割できる場合もありますし、そうでない場合もあります。そのような関係でこのような逆転現象が発生します。一口にJOINのパフォーマンスといってもこのように様々な要因が絡んできますので、一概に『○○が効率的』といえないことを表す良い例となっています。
実験2-PP ADP側でjoin(ネステッドループ&キャッシュ)でpipe実行2
実験2-Pのコードにさらにpipe述語を挿入しています。pipe述語は1つだけでなく複数入れることもできます。,$db = "DSN=Trade" ,$price = "SELECT CODE,RDATE,OPEN,CLOSE FROM Price" ,$company = "SELECT NAME FROM Company WHERE CODE = ?" ,sql( $db, $price, [], @rec) ,pipe ,sql$( $db,$company, [$rec[0]], $name) ,pipe ,csv($rec,$name).prtn,next;
実行時間は、約112秒で実験2-PPと比べて逆に遅くなっています。このように闇雲にマルチスレッドを行っても必ずしも速くならない場合がある(もちろん速くなる場合もある)のが面白いところです。pipe述語を2つ使うと3つスレッドが動作しますが、実験環境ではCPUコアが2つしかないので足の引っ張り合いのようなことになったようです。
実験3-P ADP側でjoin(事前にマップ作成)でpipe実行
続いて、実験3のコードにpipe述語を挿入しています。,$db = "DSN=Trade"
,@tbl = {}
,sql($db, "SELECT CODE,NAME FROM Company",[], @r)
,@tbl = @tbl + [ $r["CODE"] | $r["NAME"] ]
,next
,sql($db, "SELECT CODE,RDATE,OPEN,CLOSE FROM Price",[],@rec)
,$key == $rec["CODE"].str
,csv($rec,$tbl[$key]).printn,next;
実行時間は、約91秒で、実験3と比べて約18%速くなっています。
ちなみに実験3-Pからさらにpipeを挿入しても良いのですが、実験2-Pの時と同様にあまり速くならないので省略します。
結論
各実験結果を示します。
| 実験 | 実行時間(秒) |
|---|---|
| 実験1 | 119 |
| 実験2 | 117 |
| 実験3 | 111 |
| 実験1-P | 108 |
| 実験2-P | 89 |
| 実験2-PP | 112 |
| 実験3-P | 91 |
実験1~3どの場合でも、pipe述語が有効だということが分かります。これは、
・DBMSからデータを取得する
・ファイルへ書き出す
という2つのIO処理があり、pipe述語によって、それらを同時に実行することが出来る為です。
また実験2-PPと実験2-Pを比べても分かりますとおり闇雲にマルチスレッド化しても高速化が図れない場合もあります。
パフォーマンスアップは様々な要素が関わってきますので実験により確認しながらということが必要になります。
pipe述語はお手軽にマルチスレッドを実現でき、また取り外しも楽なので簡単に実験や試行錯誤が出来ます。
ADPのpipe述語はキャッシュ機能と同様に便利な道具として利用できるかと思います。
また、実験1-P、2-P、3-Pを比較しますとどれをとってもパフォーマンスにあまり差がないことがわかるでしょう。ADPの開発にあたりプログラマの自由度を高めるということも考慮しています。つまり、『○○でなければダメ』ではなく、どのアルゴリズムを採用するかはプログラマーの判断で、いか様にも選択できるような言語を目指しています。
追記:コメント欄での指摘およびテスト再現性を考慮してテスト環境を整備して再度計測しています。
2011-08-19 | コメント:0件