C言語のポインタを再考する(Part1)
- ポインタとはアドレスではなく、C言語がプログラマに公開した間接性のモデルである -
C言語を学ぶ上で「ポインタ」というのは昔からの鬼門らしい。というのは私はポインタで躓いたことがないからで、もちろん最初から全てを完全にマスターしたわけではないですが、それでも『「ポインタ分からない」が分からない』という話になります。
したがって自分のブログでポインタについての説明をしませんでした。要するに私自身「どういうふうに説明したらよいか」分かりませんでした。
一方で、とあるSNSのC言語のポインタの説明記事の
『実用上は「ポインタ=アドレス」で構いません。「XXのアドレス」を「XXへのポインタ」と置き換えても ( あるいはその逆でも ) なんら支障が出ないからです。』
というコメントを読んだ時に「ポインタが難しい」ということの底深さは少し理解しました。
良い子のみんなは真似して「ポインタ=アドレス」と言わないでねと言いたいのですが、
それだけではブログにする意味がないかと思うので、なぜ誤解なのかを説明します。
まず、言葉の意味ですが、
pointer:指し示すもの
address:住所
です。
つまり「ポインタとは道標のようなもので、アドレスとはその場所そのものの情報」ということになります。
この観点に立つと、ポインタとアドレスの違いが分かるかと思います。「ポインタはアドレスを保持する」という認識は間違っていませんが、「ポインタはアドレス」というと重要な見落としが出てきます。
C言語やアセンブリ言語に精通した人なら『”ポインタ=アドレス”ではないという」という主張には同意してもらえるかと思いますし、K&R第2版の巻末には「Is a pointer always the same as an address?」という有名な問題があります。私自身はあたりまえの認識だとおもっていたのですが、この「ポインタ=アドレス」を主張する人が日本でも海外でも一定数いらっしゃるようです。また、それなりにキャリアを重ねた人達もいらっしゃるようで、つまり「ポインタ=アドレス」という主張が市民権を得つつあるようです。
C言語が出現して50年が経ちます。私がC言語を学んだのは約37年前になります。その頃がちょうどC言語の全盛ということでした。おそらくですが、多くの人達がポインタについて十分な知識を持たないでプログラミングをしていたでしょう。ポインタに対する理解が不十分な人達は時にプログラムをキチンと動作させることができませんでした。C言語と現代の言語を例えるのならMT車とAT車ぐらいの違いがあります。つまりC言語のポインタは正しく使わないとエンストするのですが、今の言語はAT車のようにエンストすることなく、上手にポインタを隠して安全に使えるようにしています。
つまり現在の言語を主言語としている人達がC言語を横目でみると「ポインタ=アドレス」という勘違いをしても無理からぬ面もあります。しかしながら「ポインタ=アドレス」という主張はある意味でポインタの意味論を考えたときには後退した考えになります。ここら辺で一度ポインタについて再考するのが良いかと思います。
ポインタを理解する
前おきはこのくらいにしてポインタについて説明します。当初は初心者用の記事と思ったのですが、「ポインタの意義」を強調するあまり、細かな文法についての説明が完全・完璧ではないですので本当の初心者の方がこれを読んでも「?」となるだけかもしれません。解らないところはAIに聞いてもらえればよいですし、一度C言語の文法の解説を一読されてからこのブログを読まれた方が良いかもしれません。
C言語のポインタは様々な機能を実現するツールですが、ここでは
・変数の変数化
・配列の操作
について説明します。実は他にも重要な機能(関数ポインタ等)があるのですがややこしくなるので重要なこの2点に絞ります。
C言語ですが、システム記述用言語ともいわれることがあります。実は多くのプログラミング言語がC言語で書かれています。システムプログラムにおいてはポインタは中心的が技術といっても過言ではありません。実は多くのプログラミング言語の機能も内部ではポインタが使われています。ポインタとはいわば縁の下の力持ちといったところです。別の方向から見るとポインタは機械語から備わっており、プログラミングの基本とも言えますが、C言語ではそのポインタを上手く抽象化しています。
それぞれ、見ていきます。
変数の変数化(間接参照)
変数というのはある種の抽象化の機能ともいえますが、プログラムを汎用的なものにする道具でその必要性は言うまでもないでしょう。
一方で変数の変数化とは、もう一段高い、抽象化とも言えます。
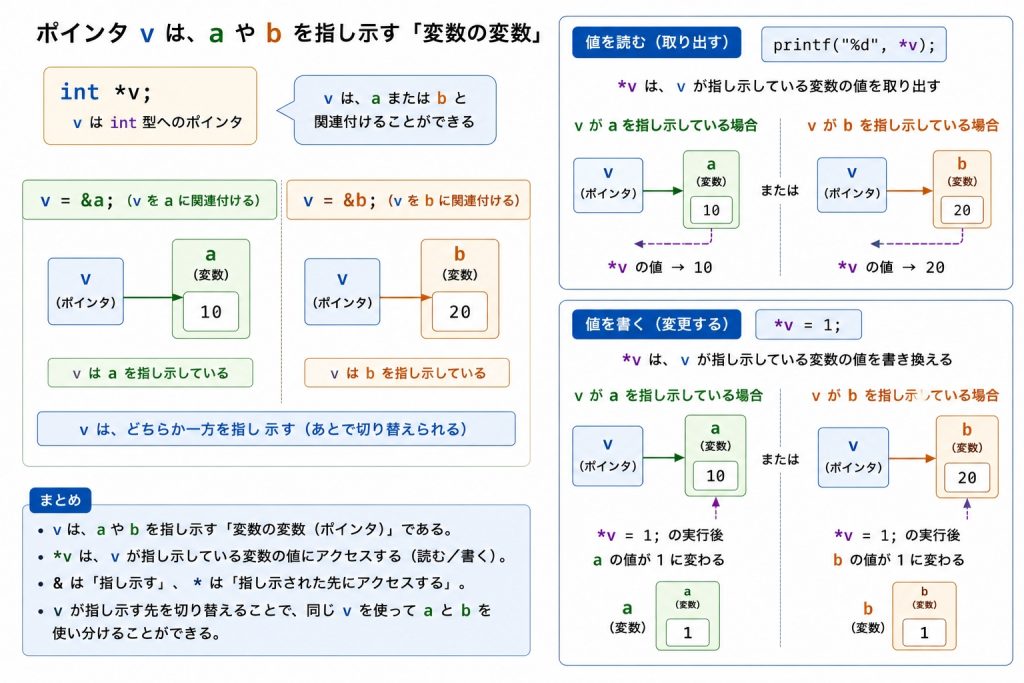
つまり、
int *v;
とすれば、
v = &a;
としたり、
v = &b;
としたりできます。これによりvはaやbと(変数の変数として)関連付けられます。
vが関連付けている変数(aやb)にアクセスしようとすると、
*v
とします。*記号は&記号の反対の操作を行うことになります。つまり
printf("%d", *v)
のように*vとするとaまたはbの値を取り出すことができます。
また、
*v = 1
とすると、変数aまたはbの値が1になります。
『これの何が便利なのか?』
と質問されそうですが、「変数の変数」と言われると、まずは「どこかで使えそう」という認識でよいかと思います。
以上、ポインタについて細部に入らないで利用目的の説明を行うと、「実体はaかもしれないしbかもしれないが値を操作したい場合は一つの変数として扱いたい場合は変数の変数化(ポインタを用いた段階的な参照(間接参照))を行うと便利ということが言えます。
具体例をだしますと関数の定義において2つの値を返そうとするとポインタを使う必要が出てきます。 整数除算を行う関数を考えます。a / b の商(d)と余り(r)を返す関数を考えますと例えば以下のようになります。
int mydiv( int a, int b, int *d, int *r)
{
if ( b == 0 ) return 0;
*d = a / b;
*r = a % b;
return 1;
}関数の戻り値で1は成功、0はゼロ割を表します。ちなみに「Cにはライブラリにdiv関数があり、しかも構造体を使って値を返しているからこの関数は無意味」とおしかりを受けそうですが、そのおしかりはそのとおりですが、私的にはたまにこういう関数を作りたくなる場合があるのも事実です。
この関数(mydivとdiv)の例は「C言語で複数の値を返すポインタを使った例」となりますが、「構造体を使えば複数の値を返せる」というのもそのとおりです。ちなみに構造体を返すのは潜在的に効率が悪くなる可能性があります。64ビット時代ではdiv関数の戻り値ぐらいですと逆にパフォーマンス上推奨される場合がありますが、構造体のサイズが大きくなるとパフォーマンスの問題が発生することを頭の片隅に置いておけば将来困らないかもしれません。
ポインタに限った話ではないですが、プログラミングの難しさの1つが「やり方が複数出てくる」ということがしばしば起こります。どちらのやり方を選ぶのか?というのは悩ましい問題となりますが、どちらを選ぶかはある意味設計の範疇になるでしょう。またこの例では必ずしもポインタを使うことが良いとは限らない例としても出しています。
話は変わって、
『「変数の変数」があるのなら「変数の変数の変数」はないのか?』
と質問されそうですが、ポインタを使えばそれも可能です。変数の変数の変数は
int **p;
と定義できるでしょう。これで、
p = &v;
として、
*p
とするとvを取り出すことができます。vは先ほどの例では、aまたはbの値を取り出すことができます。 pと間接参照を2回すれば、一気に先ほどの a または b の値を取り出すことができます。 pのことを「ポインタのポインタ」とよばれることもあります。要は*が2回出てくるのでそのように呼ばれますが、「ポインタ=アドレス」というとこの「ポインタのポインタ」を「アドレスのアドレス」という風に解釈することになります。私が「ポインタはアドレスでない」とする根拠の1つがこのポインタの機能になります。
少し話が高度になりますが、ポインタに似た機能で「参照」というものがあります。参照も「変数の変数化」を行うものですが、「変数の別名」の側面が強くなります。また、多くの言語(C言語は参照はない)でサポートされている参照は「変数の変数の変数」といった数珠つなぎ的な操作は直接は行えないです。またオブジェクト指向(肥大化した構造体をポインタで扱う)との関係で、この参照をポインタという風に認識する人達もいます(実際に一部の言語ではポインタと呼ぶ)。このような経緯から「ポインタ=アドレス」という認識が出てきたようです。
最後になりますが、変数の変数化という言葉はあまり一般的でないので、あくまでも「学習のエッセンス」として覚えていただければと思います。私自身もうあまり使わないかもしれません。
ただAIによると、C言語の解説において、「ポインタはアドレスです」という説明の次によく出てくるのが、「ポインタは、(別の)変数を指し示す変数である」という表現です。
英語圏のチュートリアルでも "A pointer is a variable that stores the memory address of another variable" という表現が頻出します。
値のコピーと変数の変数化の違い
ここで補足を行いたいのですが、ポインタが難しいところの別の理由になりますが、コピーとポインタの機能的な共通点が挙げられます。
例を出します。
int型の変数、adultprice, childprice, ageがあったとします。それぞれ大人料金、子供料金、年齢としましょう。
規則として13歳以上(12歳より上)が大人料金とします。また、actualpriceに適用料金を入れることにします。
素直にコードを書けば
/* コピー */
if ( age > 12 ) {
actualprice = adultprice;
} else {
actualprice = childprice;
}
となるでしょう。つまりactualpriceは、adultpriceかchildpriceのどちらかがコピーされます。
一方で、同じことをポインタを使ってみましょう。
/* ポインタ */
int *actualprice_p;
if ( age > 12 ) {
actualprice_p = &adultprice;
} else {
actualprice_p = &childprice;
}
actualprice = *actualprice_p;「これでは全く便利になっていない!」というおしかりを受けそうですがごもっともです。これは重要な点で「実は単純に値を変数化したいときは、『変数の変数化』を行うより『コピーを行った方が良い』場合があります(考えてみれば自明ですね)。
先ほどの例では「C言語で複数の値を戻り値とする場合、構造体にする方法もあればポインタを使う方法もある」ということですが、今回の例では『場合分けを行い値を決めたいとき、ポインタを使って複数ある値を一つのように扱える』ということが言えます。実はこの時に「値が変化しないのであればコピーで十分の場合が多い」ということがいえます。
この「コピーとポインタの役割の重なり(ポインタよりもコピーで十分)」が私なりの、ポインタの難しさの理由の1つになります。
ここまでですとポインタは使えないと判断されそうですが、もう少しポインタの利用について便利な例を次の章の最後に示します。
配列へのアクセス
C言語の、「コロンブスの卵」的な設計上のすばらしさの1つが
「配列は連続したメモリとして扱う」
ということになります。
実は、ほとんどのプログラミング言語でも、内部的に見れば、メモリの連続領域を配列として扱っています。で、多くのプログラミング言語がこの事実を隠す方向にデザインされていますが、C言語はこれを前面に出してきています。ポインタを使うと配列の要素に自由にアクセスできるようになります。
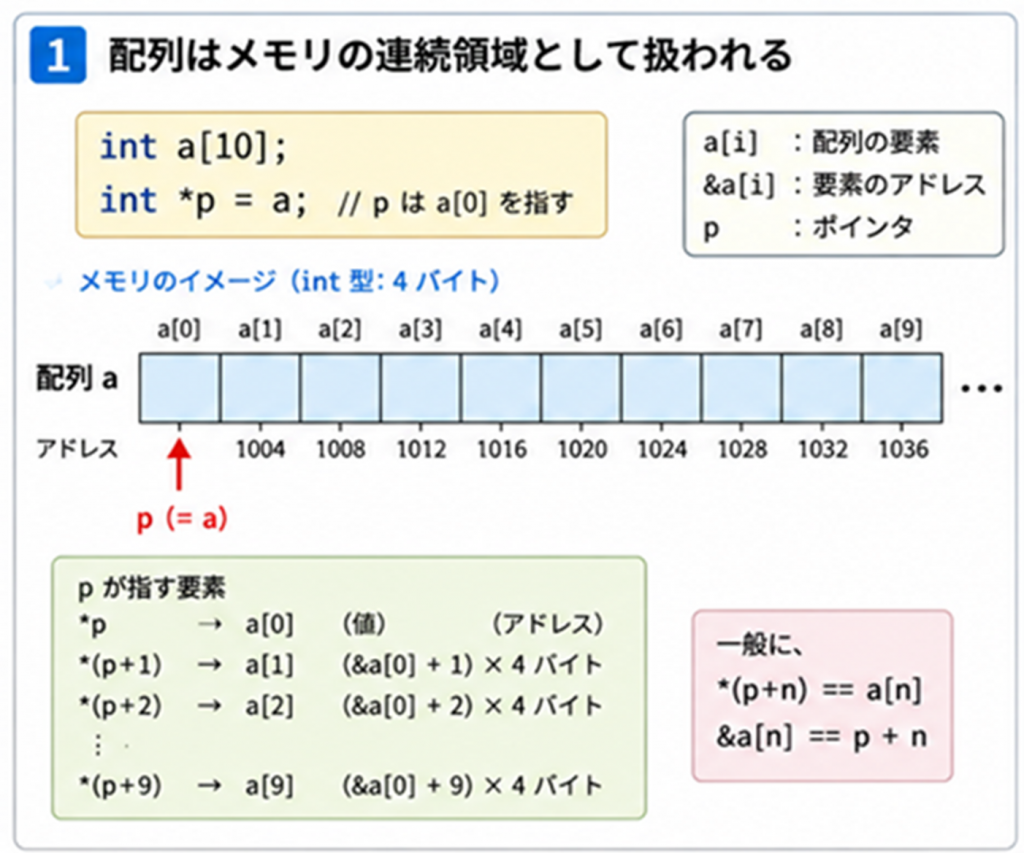
C言語では、配列は以下のように定義します。
int a[10]; /*要素数10(0~9)のint型の配列を確保(注、値は不定) */
ここで、
int *p = a;
とすると、*pは配列の0番目の要素を指すようになります。先ほどの言葉をかりますと
pはa[0]の変数の変数としてセットされます。
この0番の要素というのは決まり事になります。C言語の場合、配列の先頭は0番目ということになります。
さてここでa[1]やa[2]等にアクセスしたいのですが、pを使うとどのようになるでしょうか?
実は、
*p は a[0]
*(p+1) は a[1]
*(p+2) は a[2]
・
・
・
*(p+9)はa[9]
と言ったように関連付けられます。イメージすると下記の図1のようになります。
また、例えばですが、配列aの値の最初の5個の要素の合計を計算しようとすると
int sum = 0;
for ( i = 0; i < 5; i++ ) {
sum += a[i];
}と記述することもできますし、
int sum = 0;
int *p = a;
for ( i = 0; i < 5; i++ ) {
sum += *p++;
}と記述することもできます。イメージすると下記の図2のようになります。
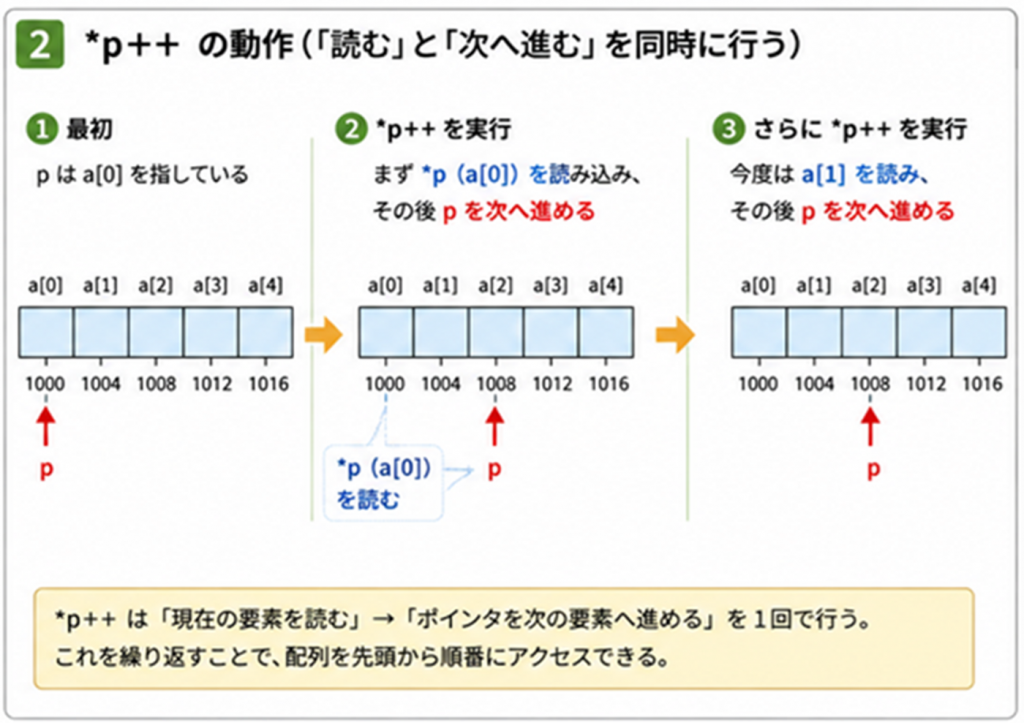
これの何が便利か?という話ですが、実は最後の
*p++
がC言語の真骨頂ともいえる記述になります。これは*pにより配列の要素にアクセスするということですが、同時に++によりポインタをインクリメントしています。このインクリメントにより配列の次の要素にアクセスできるようになります(単純にポインタに数値を足すと次の要素にアクセスできるようになるというのはメモリの連続性によるものです)。
つまり、p++とfor文を組み合わせると、
*(p + 0), *(p + 1),… *(p + 4)
と配列を順番にアクセスするようになります(図3)。

ここにさらにC言語の尖がった仕様
・文字列はchar型の配列
・文字列の最後は0
が入ると文字列のコピーは、
char dst[MAX_BUF];
char *src = "文字列";
char *p = dst;
char *q = src;
while ( *p++ = *q++ );となり(見る人が見れば)美しいコードになります。
ここまでの説明ですが、今一つ分からないかもしれません。*p++ がなぜ美しいのかを充分に理解するにはアセンブリ言語の知識も必要かと思います。
実は一部のCPUになりますが、条件が整えば*p++は1命令にコンパイルされることがあります。
さらにいうと、while ( *p++ = *q++ ); も1命令(実際には準備を行うコードが前に作られたりします)にコンパイルされることがあります。
このあたりの詳細については次回になるかと思いますが、C言語のポインタの基本のゴールの1つがここにあります。
もっとも、これで終わりではありません。この章の最後になりますが、先ほどの料金計算についてポインタを使った例を見せたいと思います。
先ほどのコードですが、料金がadultpriceやchildpriceと大人と子供それぞれ1つでした。例えば電車の運賃を考えますと料金計算は年齢および距離から計算されるでしょう。ということで、下記の仕様でプログラムを記述してみましょう。
/*料金表*/
int adult_table[4] = { 200, 270, 340, 410, };
int child_table[4] = { 100, 140, 170, 210, };
/*計算対象(3名)*/
int people_age[3] = { 20, 10, 21 };
int price_index = 2; /* 距離要素(距離テーブル配列の要素番号を指す)*/
/* コピー */
int totalprice = 0;
int i;
for ( i = 0; i < 3; i++ ) {
if ( people_age[i] > 12 ) {
totalprice += adult_table[price_index];
} else {
totalprice += child_table[price_index];
}
}
/* ポインタ */
int totalprice = 0;
int *actualprice_table;
int i;
for ( i = 0; i < 3; i++ ) {
if ( people_age[i] > 12 ) {
actualprice_table = adult_table;
} else {
actualprice_table = child_table;
}
totalprice += actualprice_table[price_index];
}となります。私にとってですが、実はポインタを使った例の方がコードの保守性(コードリーディングや変更に対する容易性)が高いです。
ポイントは料金計算をしているコードでコピー版の方はtotalpriceへの加算が2か所に分かれてしまっていますが、ポインタ版を一行にとどまっているところです。
totalprice += actualprice_table[price_index];仮にですが、大人料金・子供料金だけでなく「シニア料金」や「乳児」が足されるとコピー版ではtotalpriceへの加算を行う行が増えます。そして例えば消費税の計算を入れるとか割引処理を入れるとなるとどちらのコードのメンテナンスが厄介でしょうか?ということです。
実は、配列のコピーをおこなえば、コピー版の方でも同様コードが書けますが、C言語の場合は配列のコピーは直接サポートされていないことと配列のコピーは効率的でないのであまりお勧めできないところです。ここがポインタを使うメリットの1つです。
さらに、少し進んだ話をしますとこのようなポインタの使い方(状況に応じて対象(この場合は表))を切り替えることは、はオブジェクト指向言語では良くあるテクニックになります。覚えておいて損はないです。
さて、ポインタを使った方がコードがよりクリアーになるという話をしましたが、実は上手く配列を使えばもっと良くなります。
その例を示します。
/*料金表*/
int price_table[2][4] = {{ 200, 270, 340, 410, }, /* 大人料金 */
{ 100, 140, 170, 210, } };/* 子供料金 */
/*計算対象(3名)*/
int people_age[3] = { 20, 10, 21 };
int price_index = 2; /* 距離要素(距離テーブル配列の要素番号を指す)*/
int totalprice = 0;
int age_index;
int i;
for ( i = 0; i < 3; i++ ) {
if ( people_age[i] > 12 ) {
age_index = 0;
} else {
age_index = 1;
}
totalprice += price_table[age_index][price_index];
}料金テーブルを素直に表現している面で、私としてはこれが一番可読性もメンテナンス性も高いですが、ポイントは
・テーブルアクセスにより料金算出の一本化
・テーブルのインデックスの計算は別で行う。
ということを徹底しています。
プログラマーによっては「トリッキー」と感じるかもしれませんし、状況によると前のポインタの方が良い場合もありますが、この例から言える重要なことは、『アプリケーションプログラムを作成する上ではポインタをマスターすることは必ずしも必要ではない』というのは残念ながら今までは正当でありました。
これが、ポインタの理解がいい加減になる理由の一つかもしれません。(アプリケーションプログラム作においてはポインタに対する知識がいい加減でもなんとかなったりする)
さてこの料金計算ですがせっかくなので「サンプルから」の改善ポイントを指摘します。
・通常料金テーブルはデータベースなどに格納されているのでそこから取り出すことになります。
・今回の例では、「家族などのグループの移動」が想定されています。個別の計算も考えられます。
・いわゆるマジックナンバー(3とか12)があります。
最後のマジックナンバーについてですが、これはサンプルということでそのまま出していますが、大人と子供を分ける年齢(12)についてはテーブル化したほうがよいでしょう。具体的には、
/*料金表*/
int price_table[2][4] = {{ 200, 270, 340, 410, }, /* 大人料金 /
{ 100, 140, 170, 210, } };/ 子供料金 /
int age_rank[2][3] = {{ 0, 12, 1 }, / 子供料金対象年齢とテーブルへのインデックス /
{ 13, INT_MAX, 0 }, }; /大人料金の対照年齢とテーブルへのインデックス */
/* 計算対象(3名)*/
int people_age[3] = { 20, 10, 21 };
int price_index = 2; /* 距離要素(距離テーブル配列の要素番号を指す)*/
int totalprice = 0;
int age_index;
int i, j;
for ( i = 0; i < 3; i++ ) {
for ( j = 0; j < sizeof(age_rank)/sizeof(age_rank[0]); j++ ) {
if ( age_rank[j][0] <= people_age[i] && people_age[i] <= age_rank[j][1] ) {
age_index = age_rank[j][2];
break;
}
}
totalprice += price_table[age_index][price_index];
}となります。テーブルのバグでage_indexに適切な値が入らない場合を考慮する必要があるのですがそのコードについては省略します。
また、age_rankを2次元配列で実現していますが、本来は構造体の配列になります(こうするとDBとの相性が良くなります)。
このコードが強力なのは、年齢区分が増えてもデータ定義の部分(料金表)の変更だけで済みます。また、いわゆるロジックで使われるマジックナンバー(この場合、12)もデータ化しているのでメンテナンス性はかなり高いです。要するにアプリケーションプログラマーとしてはこのようなコードを書くことを目指そうということになります。ポインタの趣旨からは外れますがプログラミングを考えるとこういうことを言及しなければなりません。つまり「ポインタよりもこのようなデータ駆動の方法論を使う方がアプリケーションプログラムにおいては多くの場合有効である」ということになります。
補足とまとめ
ちょっと長くなり様々な論点が出てきましたが、改めて補足とまとめを行います
・C/C++言語のポインタとは、比喩的にいうと「道標」でありアドレスは「道標が示す住所」ということになります。
・変数の値にアクセスしようとした場合に、直接変数にアクセスする方法もありますが、ポインタ(道標)を使うことにより「変数の変数化」が行えます。
・「変数化された変数」を通して元の変数にアクセスすることを「間接参照」ということもあります。
・間接参照は数珠繋が行えます。つまりポインタのポインタも作ることができます。
・ポインタと似た概念(機能)に参照というものがあります。C言語では参照は直接サポートされていませんが、しばしばポインタのことを参照と言ったりします。
・C言語では配列は、連続したメモリブロックとして認識されます。
・ポインタを使うとメモリブロックに順番にアクセスする場合、p++と言った魔法の呪文が使えます。つまりfor each(やeach)と同様の機能がポインタを使えば実現できます。
・ポインタは基本的な機能ですが、C言語上でもアプリケーションプログラムを作る上では完全ではないですがポインタを避けるプログラムもできます。
・構造体をつかったりデータ駆動アリゴリズムという高水準の機能や概念をマスターすることが、ポインタをマスターするよりもアプリケーションプログラム作成においては重要な場合もあります。
・ポインタを避けることは可能ですが、C言語(その他の言語でも)ポインタを除くことはできません。ポインタはプログラミング言語を実現する上での基本機能の1つです。C言語では配列へのアクセスがポインタの利用と同一視できるようにしていますが、概念的には配列のアクセスa[i]などは表面上だけでなく内部的にも(p+1)と認識されているという関係を持つと言えます。
・ポインタは重要かつ基本的な機能ですが、一方で危険な機能でもあります。プログラミング言語の歴史上、ポインタは避けられる傾向にあります。このような経緯から誤解が発生し「ポインタ=アドレス」という認識が生まれたようです。
ポインタとはメモリアドレスそのものではありません。ポインタとは、「間接性」という仕組みをC言語がプログラマに公開した機構です。
そして
「ポインタ=アドレス」と説明してしまった瞬間に、その間接性という本質が見えなくなります。
この記事ですが、記述するのにかなりの体力を使いましたが、本来は書くべきことの半分になります。書けるかどうか分かりませんが次回の予定は『AI時代に必要な教養としてのポインタとアセンブリ言語』がテーマになります。
大学全入時代とポストLLM時代の「知性」
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
前回までで言いたいことを言ってきたのですが、Xを見ていると違和感が残る点がありましたので個別に雑記を書きます。
全入時代の違和感、足きりは必要では?
前回の記事にも書いたのですが、「誰にでも高等教育を!」というのは一見スローガンとしては美しいのですが、物凄い違和感があります。特に大学の存在理由として挙げられると矛盾を感じます。
私が18歳の時に大学に入った理由が「化学者になりたかった」のですが、入った大学の実態は「就職予備校」のようで、要するに「学生に考えさせないで上役からの命令を聞くようにする」という一種の洗脳教育のようでした。言うまでもないですが高等教育というのは「考える力を養成するところであり、(内容はどうでもいいから)期日までに指定されたページ数のレポートを書く」ということではないはずです。この手の批判をすると「今の大学は違う」という反論が来るのですが、前回までの記事のとおり、当の教える側がどこまで「学生に考える力をつけさせるか?」は疑問です。というかそもそも論になるのですが、30年前の大学と今の大学の実態がそんなに変わるのでしょうか?という疑問もあります。
大学が就職予備校でないと言うなら、企業は大学教育を職業訓練として信用しなくなる。そうなれば大学名でフィルターを掛けるのも、企業側からすれば自然でしょう。
関連してですが、当時、私自身が感じたことは、上記のような「就職予備校は要らないので、もう働きたかった」というのがあります。大学をやめる理由が後から出てきてすみませんが、当たり前ですが、大学をやめるときには色々考えまして「既にIT関係の資格を持つものとしてはわざわざ職業訓練は不要で、これなら働いた方が良い」というのも1つあります。つまり、就職予備校なら既に就職する意識や実力がある者にとっては意味がないでしょう。「誰でも入れる」というのと「皆が入る」というのは違うということです。
別の指摘になりますが、「門戸を広げるのなら、別に18歳になって大学に入る必要はないでしょう」ということもあります。『学び直しは何時でもできる』という意味での門戸を広げるのは有意義ですが、「それを学力の無い人間にまで広げるのが高等教育なのか?」ということについては疑問が残ります。例えば、小学生の範囲を学び直すのなら小学校(相当)のもので良いでしょうということです。つまり成熟した国家として学び直しのインフラは必要でしょうが、小学校の内容を大学が引き受ける必要はなく、それぞれ看板にあった教育をすれば良いということになります。
今なら本気で学び直しがしたければYouTubeでいくらでも勉強はできますが、わざわざ小学校の内容を数百万払って学ぶ必要はあるのか?ということになります。
大学関係者が偏差値について「意味がない」ということについて
意外なことですが大学関係者の方で、「偏差値は意味がない」という発言が目立ちました。
「大学の偏差値というのは、テレビの視聴率のようなもので、批判するのは構わないがある程度は受け入れる必要があるのではないか?」というのが率直な感想になります。
テレビの視聴率が悪いときにスポンサーに「視聴率は意味がないです」というようなもので、色々理屈はあるのでしょうが、入学しようとする学生に対して「偏差値は意味がない」と言われると私としては「逃げているな」としか思えません。
”Fラン”という言葉に対する大学関係者のアレルギーも感じます。これは「大学を減らせ」という議論が「Fランを減らせ」という議論に置き換わり「必要なFランもある」という論法が展開されています。Fランですが、確かに差別を伴った侮蔑的な言葉ですが、そもそもFラン(ボーダーフリー:偏差値が計算できない)という状況が本来大学に求められたものからの逸脱という点を考慮したほうが良いでしょう。それだけ魅力的な大学ではないということも言えますし、急激に大学を増やした結果の弊害とみるべきだと思います。
特に大学を減らすという政策の転換についてはこれ以上、Fランに限らずに不要な大学を増やしても社会に対してはプラスにはならないという至極当然の理由があるでしょう。
このあたりを大学関係者はどのように思っているか聞きたいものですが、この批判に対して「誰にでも高等教育を!」というスローガンで返してしまいますと「現実から逃げている」としか受け取れないです。
ちなみに私自身の話になりますが、大学をやめてから、大学中退者というレッテルを甘んじて受け入れました。何回か会社に転職もしまして、応募するときは「大卒者」ではないのでそういう企業には入れませんでしたが、そこそこいい企業に中途採用で採用されました。30年前のITエンジニアという特殊な状況だったということもありますが、募集要項に大卒と書かれても書類選考で落とされなかったこともあります。記憶は曖昧なのですが「なぜ大学をやめたのですか?」ということはあまり聞かれなかったように思います。とある企業の役員面接で「なぜやめたのですか?」と聞かれたので「こんなところを卒業したらヤバイと思ったから、実際にバブルが崩壊して同級生は就職に苦労したものもいると聞く」といったら「それは結果論だろ!」と突っ込まれましたが内定に至りました。
AI(LLM)の限界と大学教育
実は、大学関係者自身が恐らくは日々恐怖を感じながらかつどうしようもないと思っているだろうという点が、AIの台頭ということでしょう。
AIというかLLMの限界については、数理モデルからの研究があり、例えばHallucination Stations が示唆に富んだ指摘をしています。
ざっくりいうと、世の中には、原理的に膨大な計算(指数爆発)を必要としている問題があり、今のLLMが行っている計算量(N^2)では解くことができない。それでハルシネーションが起こるという話です。体感的にも分かる話ですし、実務的にはもっと様々な理由からハルシネーションが起こる(例えばそもそも学習していないことについては分かっていないがそれらしく答えてしまうなど)もあるかと思います。
LLMの台頭は明らかに一定の職業の人(特に翻訳者)から職を奪いつつあるでしょう。ただ、実際にはLLMにも限界があり、私自身は日々感じているところです。
具体的な話をするとこのブログはAIに書かせると「私自身が全く面白くなくなる」ということで自分で書いて校正させています。AIではこの論調の文章は出てこないです。
別の例を出すと、一時期「ジブリ風のイラスト」が流行りましたが、今使っている人はあまりいないでしょう。これは昔の「ホームページにFlash」と同じような印象を与えるのか、そもそも絵が「ジブリ風」であって「ジブリでない偽物」ということが伝わるのか、私は、両方だと思っています。(いま使っている人はゴメンなさい)。
上記の論文だったり私のAIとの会話での実感なのですが、ある種の楽観的なことをいうと私自身は「LLMが人間から全ての職を奪う」というのは考えられないです。多分10年も経てばLLMに対する常識ということである程度LLMの使い方が社会に浸透すると感じています。
高等教育を銘打つならこのあたりの「AIの限界を超えた教育」というものを実践してほしいのですが、残念ながら今の日本だと「国産LLMを!」と後追いをするか、AI礼賛に陥るか、少々感情的かつ的外れな批判に流れているようにも思えます。もちろんですが、深い考察を行っている研究者の方々もいますし、そういう文章も読みますが、ある意味AIに対する深いツッコミをもっと多くの研究者に期待したいところですが、昔話のような「内容はどうでもよいが指定されたページ数のレポート書く」という課題を与えていた大学にできるのでしょうか?
そうは言ってもAIは世の中を変える
上の偏差値の話と一見矛盾しますが、LLMの台頭により、「知性のランク付け」というか、大学のランクというものも変わる可能性があるでしょう。つまり従来型のテストで測る知力というのはLLM時代には意味のないものなりつつあります。過去の例をあげると、2026年現在、社会人として漢字を手書きできないということはあまり問題にならないでしょう(実際に私は多くの漢字を書けないです)。一方で、40年前(1986年)当時なら多くの人が手書きで文章を書いていましたので、漢字が書けないということは知性がないとなったでしょう。
もっというと綺麗な文字を書くということも言われました。私の書く文章は汚いのでよく親に注意されましたが、今なら笑えない昔話ですね。
40年前と言えば、仕事でコンピュータを使うということはあまりなかったかと思いますが、今ではパソコンが使えない人は就職もままならないでしょう。
LLMが起こしているパラダイムシフトはもっとラジカルなものでしょうが、本質的には「人間の知性についての再定義をせまっている」とも言えるでしょう。
LLMが東大の入試問題を解いたというニュースは「実は東大の入試問題はそれほど知的ではなかったのか?」という問いかけを我々に投げかけます。この事実とハルシネーションの間に、「パラダイムシフトへのヒント」が隠されているように思えます。「偏差値は意味がない」という関係者の方はぜひ、LLM時代の人間の知性について議論をしてほしいものです。
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:SNSでの大学のリストラの議論で思うこと
高等教育者は、悪いリストラに立ち向かえるのか?
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
いくら「大学は必要なんだ!」、「地域に不可欠だ!」と叫んでみても、それは今までも多くの人が叫んでいたことで、ある意味リストラされる側のテンプレでしかないでしょう。
と前回の記事に書いたのですが、要するに私としては「あまり細部には入り込みたくなかった」ということなのですが、Xで興味深い議論にもなったのでちょっと突っ込みます。
良いリストラと悪いリストラ
今の日本はざっくり言って、「30年リストラし続けて、さらに状況が悪くなり、今は大学の番(が目立つ)」ということになります。
風が吹けば桶屋が儲かるではないですが、失われた30年の結果、子供の数が減り、今大学の数が減ろうとしています。
前回私は、「就職氷河期世代の人材の質の高さには、高等教育の拡大も一定程度寄与していたのではないか」という仮説を書きました。
それが正しければ「その大学が減り、学生の選択肢が無くなればさらに日本人の人材の質が下がるのではないか?」という問いはYESということになるかと思います。
もっとも、少子化ということで大学が減っても減らなくても、残念ながら日本人の人材の質は低下しているようですが、それに拍車がかかるということです。
いずれにしても、
大学を減らす → 人材の質が下がる → 国際競争力が低下する → 所得が下がる → 少子化が進む → 大学が定員割れを起こす。
となるかということになるかと思います。
つまり、この30年の「デフレスパイラル」が、「人口減少スパイラル」に変化したともいえるでしょう。
日本の場合、リストラすれば状況が良くなるということではなく、さらに問題が悪化してきました。なぜでしょう?
リストラが行われた場合、傾向として「能力の高い人から辞めていく」というのがあります。日本の場合、終身雇用となっており、ある意味、頑張れば会社に残ることができます。
結果として、能力の低い人が会社に残ることになります。そして業績がさらに落ち、さらにリストラをするという悪循環になっていました。
これで、会社が潰れ、新しい会社が興ればむしろ良いのですが、残念ながら日本の場合、「能力が高いからと言って必ずしも転職や起業が成功しない」ということもありました。これは村社会ともいえることで、能力の高い人が起業しても取引をしないということがあります。
私の場合は、会社を辞めてどうなったかというと、流れ流れて幸運にも外資系の企業と取引をするようになりました。
独立後、あるとき、そこそこの規模の日本の企業と取引をしたのですが、営業担当と話をしたときに、彼の「そうか零細企業なのね。じゃ幾ら俺にバックをくれるんだ。」というようなあからさまかつ日本的なやり取りがありました。搾取しようとしたのが見え見えで、私としてはフェードアウトさせていただきました。
このように日本の場合は、悪いリストラが行われたということになります。
では、良いリストラとは何でしょうか?
外国の企業の場合、「経営が悪くなれば先ずは経営者が変わる」という傾向があります。最近の例では、2024年末にインテル社のCEOが変わりました。私も身近に「社長が切られた現場」を見てきました。こういうある種、合理的かつ責任の所在がはっきりしている現場では、経営者が変わることにより業績が上向く可能性もありますので従業員がリストラされることもないでしょう。経営者が変わっても業績が上向かないということは「市場の失敗」ということでシュリンクするしかないですが、責任の所在や状況がはっきりとしているので最終的にリストラされる労働者の方も納得感はあったかと思います。
つまり、一律に数を減らすのではなく、責任の所在をはっきりさせることにより、リストラされるべきところをリストラし残さないとダメなところは残すということが行われます。
日本のリストラの場合は、責任の所在がはっきりしないので、結局一律カットということが行われます。
大学を例にとると、大学経営の失敗なら経営者が責任を取る必要があります。それに加えて、甘い見通しで設置を認可してきた行政側、大学を政策や天下りの受け皿として利用してきた側にも、責任の所在を明らかにする必要があるでしょう。
もちろん、個別の企業では、日本でもキチンとしたリストラをやっていたり外国企業でも経営者が居座るということもあるでしょうが、国全体としてみれば日本は残念ながら悪いリストラの方が多かったということが言えるでしょう。
要するにリストラにも良い悪いがあり、
良いリストラ:責任の所在とカットの理由が明確、悪循環になる恐れが低い。
悪いリストラ:責任の所在が不明確、一律のカット、良い人材から抜ける、悪循環になる恐れがある。
ということです。
問題意識がある人と分かっていない人
大学を減らせというと、条件反射的に拒否反応をする人の中に混じって、ある程度、状況を理解していると感じた投稿もあります。
このままいくと、問題意識がありかつ物分かりのよいある意味、再建に適した人材から辞めていく恐れがあるでしょう。そうすると回りまわって・・・ということになります。
この悪循環を止めるのは、責任の所在をはっきりさせながら、適切な人材が大学に残るようにする必要があるでしょう。
一方で、条件反射的に拒否する人は、現状維持では何も解決しないことを理解された方がよいかと思います。
例えば下記のような投稿をする人には、「見識とは何ぞや?」と考えさせられます。
『Fラン潰せ論でクソリプ投げてくる人の言動・見識が現実のFラン学生以下で、やっぱりFラン要るなって気持ちになってる。』
上記の投稿には、ある種の歪んだエリート意識が垣間見えます。
実は、私が大学をやめた別の理由に『学生の意識の低さ』がありました。確かに当時の大学の進学率は20%程度で、大学に入れば就職できる「レールに乗れる」という空気があり、ある種の『間違ったエリート意識』がありました。思考を停止して『これでいいんだ』というおめでたい人達がちょうど『内定取り消し』の時期にあたり文句を言っていたことを思い出しました。
誰にでも高等教育をという理想を実現するには?
Xでの議論になったのは、「誰にでも高等教育を!」という発想が見えたので聞いてみたらそのとおりだったということです。
私が高校に入学して、初めての三者面談で先生から言われたことが、「うちの学校からは大学は行けません」という話でした。
確かに今は「大学全入時代」ということで、「誰にでも高等教育を!」ということでそれはそれで理想が実現したかと思います。
一方、現実をみますと、就職氷河期やリストラというのが多くの日本人を苦しめてきた事実があります。
このような方達は今の「誰にでも高等教育を!」と言っても白けてしまうだけでしょう。「パンが無ければケーキを」に近い違和感を感じることでしょう。
大学の関係者は、まさにリストラを目の当たりにした今、就職氷河期やリストラが、如何に多くの日本人を苦しめてきたか?というものを実感し、今こそ、その知性を発揮して、「責任の所在の追求と破滅的なスパイラルの停止」に尽力するのが筋かと思います。
そういう力を持った方達から理想的な高等教育を受けた学生は日本を復活させることができるでしょう。
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
大学のリストラがはじまるようだ
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
どうもSNSが、Fラン大学を潰せ vs 潰さないで騒がしいなと思ったら、こんな記事が出ていたらしい。
私立大学250校削減案、財務省が2040年目標…文科相「機械的判断ではなく分野や地域バランスが重要」
実は、前の記事で書いていた私がやめた大学ですが、入学当時は偏差値は不明(我ながら呑気な高校生でした)で、後から50程度と知ったのですが、改めてみたら偏差値が40台になっており、やめた大学とはいえランクが下がったことに若干ショックを覚えています。
定員割れが50%
記事によると、2025年で、私立大学の半数が定員割れを起こしているとのことで、大学の削減やむなしといったところかと思います。
2040年で250校というとざっくり言ってこの30年間で増やした数を減らすということのようです。
つまり、この30年間で行ってきた大学数を増やすという政策が効果がなかったといっても過言ではないでしょう。
こういうと、反論がきそうなので一つ指摘しておきますと、仮に大学数を増す、つまり高等教育の機会を増やした結果、本来なら日本人の知識なり教養が増えて然るべきだと思われるが、そういう成果の話はあまり聞いていなく、「Fラン大学が小学校の教科をやる必要性」とか「地域に必要な人材を」とかを強調する話が聞こえてきます。
この30年の大学数の増加と日本人の知力の変遷
さて、この30年で大学の数が増え、大学への進学率も向上しましたが日本人の教養というのは伸びたのでしょうか?記事では、
『「四則演算から始める。少し背伸びして微分などの理解」「(英語の)文型の基本とbe動詞の整理」などを挙げた。「義務教育で学ぶ内容の授業が行われている大学もある。助成金の支出に見合った教育の質が確保されているか疑問だ」』
と言ったように、是非はともかく、必ずしも大学で教える必要がないことがやり玉に挙がっています。
別の例として、1つ数字をあげると、日本人のIQは世界で1,2を争うらしく、2025年の調査で大体110前後(105~112)とのことです。昔の日本人のIQは、この記事だと2006年で105、この記事は2004年のもので115とあります。つまりここ20年間日本人のIQは変わっていないということになります。
大学教育とIQを一緒にするなと言われそうですが、さらに別の例をだすと還暦近い人なら80年代当時、『日本人はアメリカ人より頭がよい』という認識があったかと思うが、今はそういう話もあまり聞かなくなりました。
大学等中退者の就労と意識に関する研究によると、偏差値が39の大学の退学率は17.2%、40-44でも16.9%と高い。一方、偏差値50では、6.8%でそれ以上だと中退率が下がるということを考慮すると、入りやすい大学と学生のミスマッチが起こっていることを示唆している。17%というのは無視できない数字であり学生からみたら偏差値が低い大学はリスクが高いともいえる。
いずれにしても、大学の数が増えたことで日本人全体の知的水準や教養が目に見えて底上げされた、という実感はあまりありません。
大学増加が就職に貢献したか?
ちなみに、日本人のIQは世界トップクラスなのにここ30年経済成長していないというのはパラドックスだと思います。ここ30年リストラの現場を見てきましたが、必ずしも「能力が無いからリストラされる」というわけではなかったのである意味同情する余地があり残念な時代でした。
別の例をみると、90年代から、「就職氷河期」と言われて大学生の新卒採用が困難になりました。この原因ですが一般論として「バブル崩壊」という認識があったかと思いますが、「企業の求人数は増えていないのに、新卒の学生の数が増えたので溢れる学生が出てきた」ということも言えるかと思います。これは結局、学歴フィルターという言葉が出てきたことでも分かるとおり、増えた大学がそれほど魅力的ではなかったともいえるのではないでしょうか?
反論はあるでしょうが、大学関係者の方は、このあたりのことをもう少し誠実かつ真摯に受け止めた方がよいかと思います。特に学生に数百万の学費を払わせる価値があるのか?今一度自身に問いかけて見てはいかがでしょうか?
攻撃ばかりではなんなので、1つ大学側の擁護ではないですが、成果の可能性として、「就職氷河期の人材の質の良さ」があるかと思います。非正規労働が増えているにも関わらず少なくともこの30年間は日本は「安全で安心な国」でした。例えば、JR東日本の新幹線のトラブルが2024年9月と2025年3月に続けて起きていますが、それ以前は新幹線がトラブルというのは考えられませんでした。
通訳案内士として外国人に日本を紹介するときに「日本の鉄道技術は世界一で安全かつ正確です」と言っていたのですが、最近はそういう説明も憚られるようになりました。
これについては、「人材の質が落ちているのではないか?」という話もありますが、ようは労働者の絶対数が減ったということで、逆に失われた30年の中でも日本人の技術力の高さを物語っていたということが言えるかと思います。
そして大学の番になった
私がリストラという言葉を初めて聞いたのは90年代後半だったかと思います。衝撃的だったのは、当時、近所のファミレスに中高年の男性がウェイターとして働いていたことで、不景気を実感しました。
その後、ITエンジニアということもあり、ある意味リストラの片棒を担ぐ立場でもあり、リストラの現場をしばしば目撃しました。私自身がリストラ(お役御免)となったこともあります。
様々な業種、シャッター商店街やら、銀行や証券会社の破綻からはじまり、自動車、デパート、航空会社、電器産業と様々な業種にリストラの嵐が吹き荒れたかと思います。
そういうものを見てきた身としては、「あー今大学なんだー」というのが実感です。
リストラされそうな大学関係者の皆様は、いくら「大学は必要なんだ!」、「地域に不可欠だ!」と叫んでみても、それは今までも多くの人が叫んでいたことで、ある意味リストラされる側のテンプレでしかないでしょう。
2040年ということは後14年間ということですが、削減はそれ以前から進むでしょうから、お早めの準備をお勧めします。
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
大学だけが人生でない
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」
タイトルの言葉は私が高校生の時にクラス担任の先生から言われたことです。今となっては彼のいうことは間違っていなかったと思いますが、今から37年程前は勇気のいる言葉でした。
入学後に、テレアポの電話がかかってきて適当に流していたら『倍率7倍なんてすごいですね』と言われて自分の大学の倍率を知りました。ちなみに受かった理由は「運が良かった」で大学名は敢えて出しません。
その3年後になりますが、大学を辞めるときに当時のクラスメートから言われたことは「お前の人生終わるぞ」で、当時の一般的な感覚を示しています。まぁ、今となっては思い出の1つです。
やめた理由は、ここの「3.大学教育について」に書いてあるので、繰り返しませんが、私から見れば今の大学が置かれた状況を見ると「そうだろうな」という印象です。
あれから私も還暦を控えた身になりますが、少子化の影響で大学全入時代を迎え「Fラン大学」、「Fラン行くなら高卒」という言葉が出てきて隔世の感があります。
正直、大学に行くか行かないかは本人たちに任せればよいかと思いますし、Fラン大学が潰れようが残ろうが「それは社会(学生)からの選択の結果だろう」と思います。
強いて学生の方に補足すると、大学を出ていきなり数百万の借金(奨学金を含む)を背負うのはリスクがあるので、特にFラン大学へ借金してまで入学するのは個人的にはお勧めしないということと、今はSNSの時代なので、大学関係者の書き込みを見て、受験の判断をしてもよいかと思います。
今の奨学金は「教育のための支援」ではなく、実質的には「将来の収入を前提とした借金」
あくまでも私の記憶ですが、奨学金って月に5万円程度しか借りられなく、あくまでも補助的なものでした。当時の多くの学生は無利子または低利息だったこともあり、小遣いを借りるという感覚だったかと思います。4年フルに借りても総額で240万円程度で、これなら車のローン程度になるかと思います。もちろん当時の経済状況(好景気)もあり決して返せない金額ではありません。
一方で今はもっと借りることができるようで、卒業後300万円とか400万円、多い人だと600万円を超える借金を背負うことになります。例えば消費者金融から借りるには年収の1/3という規制があるのですが、下手をすると年収以上の金額を借りることになります。
もちろん、奨学金と消費者金融では利息が違うので一概にNGとは言えませんが、それでも卒業後、キチンとしたところに勤められなければ借金が重荷になるでしょう。「結婚相手が奨学金を借りているので躊躇している」、「奨学金も借金」というSNSの書き込みも目にし、奨学金の負担が1つの社会問題になっているかと思っています。
高校生の方は、奨学金の現状と解決策というPDF(2025年6月)があるので一読することをお勧めします。特に奨学金を借りて進学することを予定している皆様は、ページ10,11の部分、
- 若者にとって奨学金返済の負担は大きく、将来の生活設計の見通しが立ちにくくなっています。
- 若い世代がもっと前向きに安心して人生設計出来る持続可能な社会へ向け、奨学金制度の改善・改革が求められています。
- 人生の選択に対して二の足を踏む、躓きの大きな原因のひとつになっている
を読んで真剣に自分の人生について考えた方がよいでしょう。借りなければこのような負担はないということを考慮に入れ、借りるときは覚悟を持って借りましょう。
制度としての奨学金については大人が考えればよいのですが、社会のことを充分に理解していない学生に対して、経済状況を踏まえると返済できるかどうか分からない借金を背負わせるこのシステムには、問題があると言わざるを得ません。
高校生の方は『Fラン大学で奨学金を借りるということはリスクがある』ということは理解しておいた方がよいかと思います。
借金をさせてまで維持する価値が、今の大学組織にあるのか
この記事の発端ですが、ある大学関係者の方の書き込みですが、特定して批判するのはあまりよくないかと思いますので濁しますと、
批判者:Fラン大学に行くなら高卒でよい
大学関係者:『大学は学問をやる場所(だからFラン大学は不要)』という意見=大学に対する解像度が低い
というコメントで、率直な意見を言うと「そんな認識でFラン大学を擁護しているのなら、そういう大学は要らないだろう」ということです。
ざっくり今の状況をいうと、「学生の数が減って大学が過剰になっている」ということで、処方箋としては「大学の数を減らす」というのが、まず第一に考えるべき点でしょう。
つまり、大学もリストラを受ける時代になったということで、これについては受け入れるというのが一つの回答になります。
ここで、Fラン大学の社会的な存在意義を唱えるのなら、
『大学は学問をやる場所(だからFラン大学は不要)』という意見=大学に対する解像度が低い
こういう風に批判者を批判するのではなく、キチンと、そのFラン大学の存在価値を示せばよいのです。まさに説明能力こそが高等教育の証ではないのか?と思います。
それを高等教育を行うものがステレオタイプ的(反射的)に批判者を批判すれば「あーこういう説明能力のない人が大学やっているのなら無くてもいいかな」と思ってしまいます。
ITエンジニアでしたら、コミュニケーション能力が求められます。例えば客から問題点を指摘されたときに「お前の意見の解像度は低い」と言えばそういうエンジニアは退場させられるでしょう。
通訳案内士にしても同じです。
ある程度ランクの高い職業や専門職(ITエンジニアもそうですし通訳案内士もそういう面はありますが)の方は議論になると相手が無知ということで論争に勝とうとする面がありますが、ここで問われているのは説明責任でしょう。
日本経済の30年にわたる停滞を踏まえると、高等教育が十分に機能してきたのかという点について、考えさせられる書き込みとも言えます。
この方のSNSを見たのですが、既に学部単位ではリストラが始まっており「死活問題」と言っているのですが、これはあくまでも大学(教員・関係者)の立場からの意見であり、この方の大学もいわゆるFランで本人にとっても死活問題なのでしょう。もっともリストラというのは現代の日本のビジネスパーソンにとっては避けて通れないので頑張っていただくしかないでしょう。
私としては、不要な大学は淘汰されて、無理をして借金をしてまで大学にいくより、高卒でもキチンと仕事ができる環境の方がより社会にとっては良いかとは思います。今の私の年代(還暦近く)の人の半数以上は高卒です。
ちなみに、IT系の資格は高校生から取得しており、通訳案内士の資格は社会人(40代)で取得しました。どちらも大学で勉強したものではありません。
資格もそうですし、私は放送大学を卒業しており、働き出してからでもやる気があれば大卒の資格は取れるのでそういう努力が報われる社会になれば良いかと思います。
改めて「あの時は、大学をやめて正解だった」と個人としては思う日だった。
Part1:大学だけが人生でない
Part2:大学のリストラがはじまるようだ
Part3:高等教育者は、悪いリストラ に立ち向かえるのか?
Part4:大学全入時代とポストLLM時代の「知性」