変数は「箱」か「名札」か?― 初心者教育から束縛モデルまでを考える
以前、「変数は箱か名札か?」で動画を上げたのですが、あまりアクセスはなかったのですが、最近少しアクセスがあり、改めて見たら面白かったので、もう少し突っ込んでまとめてみました。
プログラミング教育の現場では、今も昔も「変数とは何か?」が最初のハードルです。
伝統的には「変数は値を入れる箱」と説明されますが、
最近では「変数はオブジェクトに貼られた名札(ラベル)だ」と主張する声も聞かれます。
一見、単なる比喩の違いのように見えますが、
この議論の背後には、プログラミング言語の理論と設計思想の根深い違いがあります。
ここでは、初心者教育から理論的背景、そして実用上の含意までを整理してみます。
Ⅰ. 初心者教育での「箱」モデルの意義
最初に登場するのが、もっとも直感的な「箱」モデルです。
変数とは、値を入れておく箱である。
a = 1
b = a
a = 2
このとき、a の中身を 2 に変えると、b の値はそのまま 1。
学習者は「箱に入れた値を取り出して使う」イメージで簡単に理解できます。
C や C++ のように、メモリ上の領域が実際に割り当てられる言語では、
この比喩はきわめて正確であり、教育的にも有効です。
Ⅱ. 「名札」モデルの登場と混乱
一方で、Python や JavaScript では、変数の実体がやや異なります。
これらの言語では、変数はオブジェクトへの参照を持つ仕組みであり、
代入は「名札を貼り替える」動作に近いのです。
変数は、オブジェクトに貼る名札である。
a = [1, 2, 3]
b = a
a[0] = 9
ここで b を出力すると [9, 2, 3]。
箱モデルでは説明しづらく、「名札モデル」の方が合うように見えます。
しかし、注意すべきはこの比喩も完全ではないという点です。
配列の各要素 a[0] にまで「名札」を持ち込むと、
今度は配列の連続性やメモリ構造のイメージが崩れてしまいます。
結果として、初心者をさらに混乱させることもあるのです。
Ⅲ. C/C++が示す「共存モデル」
C や C++ では、値型と参照型(ポインタ型)が共存しています。
int a = 1;
int &r = a;
このとき r は a の別名であり、どちらを変更しても同じ領域が変化します。
つまり C++ は、「箱」と「名札」の両方の性質を明示的に区別できる言語です。
教育的にはこの構造が非常に有益で、
物理的なメモリ構造と論理的な参照概念の橋渡しを学ぶことができます。
ただし、ポインタや参照はプログラミングの初心者にとっては難しい概念である。
Ⅳ. 関数型言語における「束縛モデル」
さらに理論的な世界へ進むと、
「変数は値を入れるものではなく、“値(あるいは式)に束縛される名前”だ」
という考え方が登場します。
束縛(binding)=変数と式の対応を定めること。
Haskell などの関数型言語では再代入ができず、
変数は一度束縛されたら変更できません。
x = 1
y = x + 2
このとき x や y は「箱」ではなく「式の定義名」です。
評価は遅延的に行われ、必要になるまで実際の値が求められません。
この仕組みは理論的には非常に美しく、
純粋関数・副作用の排除・数学的推論のしやすさといった利点をもたらします。
Ⅴ. 束縛モデルの強みと限界
束縛モデルの最大の利点は、式そのものをオブジェクトとして扱える点です。
たとえば、自動微分やDSL(ドメイン固有言語)の分野では、
式構造を保持して解析・変換する必要があります。
しかしその一方で、束縛モデルには現実的な制約もあります。
| 項目 | 束縛モデル(遅延評価) | 参照モデル(即時評価) |
|---|---|---|
| 抽象性 | 高い | 低いが直感的 |
| 実装効率 | 低い(オーバーヘッドあり) | 高い |
| デバッグ | 難しい(評価タイミング不明) | 容易 |
| メモリ予測 | 困難 | 明確 |
結果として、実用言語の多くは参照モデルを基本にし、
必要な箇所だけ束縛的な振る舞いを導入する設計を採用しています。
Ⅵ. 束縛モデルが主流にならなかった理由
-
- パフォーマンスとメモリ効率の問題
遅延評価や式構造の保持にはコストがかかる。
- パフォーマンスとメモリ効率の問題
-
- 最適化の困難さ
コンパイラが静的解析しにくく、最適化しづらい。
- 最適化の困難さ
-
- デバッグや可視化が難しい
どの時点で評価されたかが分かりづらい。
- デバッグや可視化が難しい
-
- 実際に必要なケースが限られている
自動微分やDSLなど一部領域に限定される。
- 実際に必要なケースが限られている
Ⅶ. 現代的アプローチ:必要な部分だけ「束縛的」に
今日では、C# の Expression<T> や
Python の sympy / jax、
C++ の Expression Template など、
必要な箇所だけ束縛モデル的挙動を模倣する仕組みが採用されています。
つまり、
「束縛モデル全体を採用するのではなく、
その一部を道具として使う」
という方向に落ち着いています。
Ⅷ. 教育的まとめ:段階的理解のすすめ
| 学習段階 | 目標 | モデル | 教育上の重点 |
|---|---|---|---|
| 初級 | 値の代入と操作の直感的理解 | 箱モデル | シンプルな心象で理解する |
| プロ(中級) | メモリと参照の関係を理解 | 箱+参照モデル | オブジェクト共有・ポインタ・参照 |
| 研究レベル | 抽象的な束縛・遅延評価・純粋関数 | 束縛モデル | 数理的抽象化・関数をデータとして扱う |
Ⅸ. 結論:「名札」は“箱”を超えるものではない
「名札」や「束縛」という比喩は、
実行環境や抽象化の観点を説明する一つの手段に過ぎません。
しかし、それを「箱より優れている」と主張するのは誤りです。
比喩はあくまで教育のためのツールであり、
言語設計の本質はメモリ・参照・評価戦略の選択にあります。
実務的な観点から見れば、
「箱モデル+参照の理解」で十分に事足り、
束縛モデルは特定分野での理論的・実験的意義を持つに留まります。
最後に:比喩の目的を取り違えない
変数を「箱」と呼ぶのも、「名札」と呼ぶのも、
プログラミングという抽象世界を理解するための足がかりに過ぎません。
重要なのは「どの比喩を使うか」ではなく、
その比喩がどの抽象化層を説明しているのかを意識することです。
プログラミング教育において本当に求められるのは、
比喩をめぐる正しさの議論ではなく、
学習者が言語の階層構造(値 → 参照 → 束縛)を自然に昇っていけるように導くこと
なのかもしれません。
この文章は、ChatGPTとの共同作業により作られています。
マルチスレッド&アセンブラプログラミングをしてみる(コラッツ予想のプログラム)
多コアCPUのコアを使い切るにはどうするか?とここ数年考えていたのですが、そういえばコラッツ予想(3n+1問題)を確認するプログラムはちょうどよい例だと思いプログラムを作成してみました。
CollatzAsmについて
せっかくなので64ビットアセンブラで作成し、128ビット(2の128乗)までの数を扱えるようにしました。ちなみに64ビットだと入力が数百億程度(35ビット程度)で内部の計算が桁あふれを起こします。
Visual Studio 2022(C++/Asm)で作成しています。ここからプロジェクトファイル一式をダウンロードできます。
Visual C++ですが32ビットバージョンはインラインアセンブラが使えるので、お手軽にアセンブラを使えたのですが、64ビットになりなぜかインラインアセンブラをサポートしなくなりました。ということで約30年ぶりにアセンブラのソースコードを書きました。
ちなみに、16ビット時代はアセンブラプログラミングの参考書が豊富にあったのですが、64ビットになりあまり見当たらなくなりました。昔はミックスドランゲージといって、Cからアセンブラを呼び出す方法もよく解説をされていたのですが、今では、ここに資料があるくらいで、基本的なことが分かっている人じゃないと意味不明かと思われます。
詳しい解説はご希望があればやりますが、このプロジェクトをサンプルとしてもらえればと思います。
また、このサンプルはC++14のマルチスレッドのサンプルにもなっています。長い間マルチスレッドプログラムと言えばOSのAPIかランタイム関数を使って作っていたのですが、C++14からプログラミング言語にサポートされたということで作成してみました。
実行例は以下のとおりとなります。
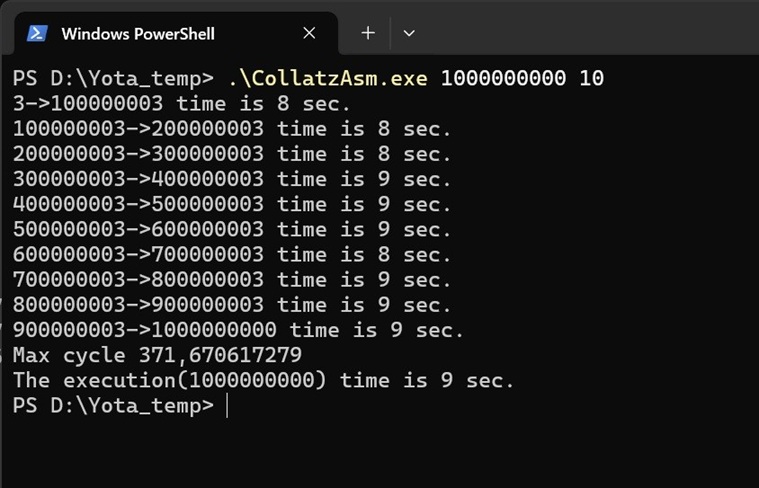
最初の引数で何処までの数を確認するかを入れ、2つ目の数は並列度(スレッド数)になります。
サンプルでは10になっていますが、当然コア数以上の値をいれます。32論理コアに対して100とかにしてもパフォーマンスが上がります(後述)。
CollatzAsmBenchについて
アセンブラでのプログラミングに限った話ではないのですが、プログラムの最適化の過程で試行錯誤を行うことがあります。特にアセンブラでプログラムすると様々な命令を使うことができるのでそのバリエーションが増えるかと思います。
ということで試行錯誤の記録として10個程アセンブラのコードのパフォーマンスを比較するプログラムを書いてみました。
以下、実行結果になります。
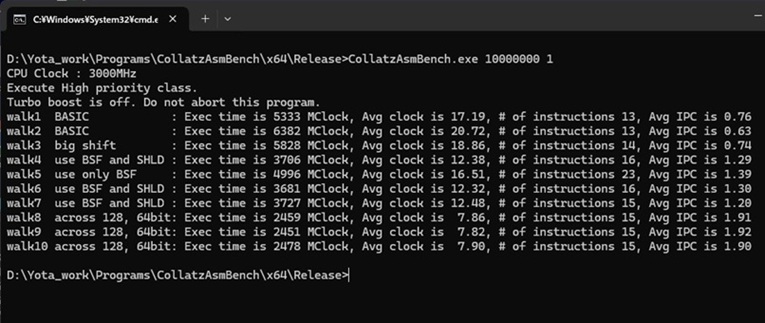
ChatGPTの出力コードとの比較
いわゆるバイブコーディングということで専用のツールも出てきていますが、コラッツ問題を扱うプログラムに関していうと、どこにでもあるのでChatGPTでも簡単なプロンプトでかなりいい感じのコードを出力しています。ということでChatGPTでプログラムを出力させてみました。、実際に試してみたところ可能でしたがあまり速度が変わらなかったので、今回はアセンブラでの出力はしていません。ChatGPTが作成したマルチスレッドのものを掲載します。
私が作ったコードと比較するとマルチスレッドの初期化の取り扱いがうまいです(emplace_backを使っている)。一方で、データ長は64ビット止まりで、並列性も論理コア数に従ってスレッドを作成していますが(hardware_concurrencyメソッドを呼んでコア数を取得している)、このプログラムの場合、各スレッドの実行時間が必ずしも同じではないので、スレッド数をより多くして各スレッドのタスクを細かくした方が、実行時間のばらつきの減少が期待できます。一方で、一般論になるのですが、論理コア数以上のスレッドを実行させると各スレッドがCPUのリソースを食い合いすることになるので、実行スレッド数を論理コア数に合わせるのも一つの手になります。
今回はアセンブラでは比較をしませんでしたが、CやC++のコードを単純にアセンブラにしてもあまり早くならないということもあります。一方で128ビットのような桁数の多い計算をさせる場合、アセンブラには桁あふれを処理する命令があり、CやC++で組むよりはるかに効率的なプログラムが記述できます。機会があればChatGPTでアセンブラプログラムの最適化を行いたいですが、↑の例にあるようにAIに任せるより、自分で工夫をした方が手っ取り早い面があります。もちろんですがアイデア出しをAIに頼ることもできますので、こういうことではあまりAIと人間の比較は意味がない(人間からしたらAIも利用する)ということになりますが、2025年9月現在、このあたりのチューニングはまだ人間の方に一日の長があるかと思います。(追記)この記事の公開後、1週間でClaudebotと名乗るロボットからZipファイルがダウンロードされたのでひょっとしたらClaudeにコードがパクられるかもしれません。
最後に実行結果を
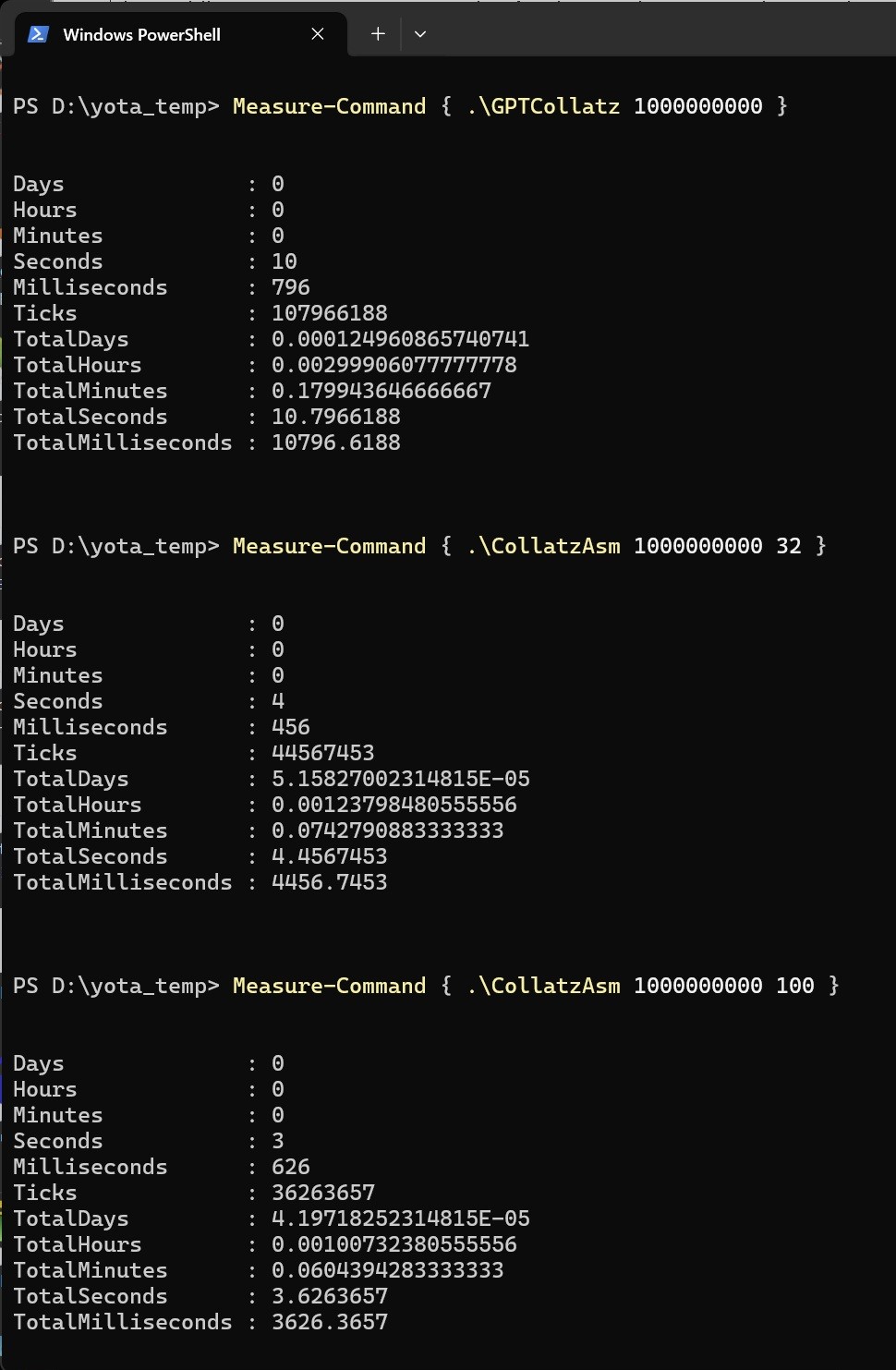
ということで、倍以上のパフォーマンスを示しています。逆にいうと倍程度にしかならないのですが、ある処理時間が半分になるということは2020年代のCPUの進化でいうとほぼ10年に相当します(この場合シングルスレッド性能の比較になる)。つまり上手くアセンブラでプログラムを書き直すことができればCPUの進化を10年先取りできるとも言えます。CPUのシングルスレッド性能の向上が顕著だった90年代ですと概ね1,2年でパフォーマンスが倍になっていました。
余談ですが、アセンブラでのプログラミングは8ビットや16ビットの時代は割と一般的でした。90年代以降ではCPU自体の進化が早かった為、アセンブラでのプログラミングがエンコードなど、いわゆるSIMD命令を使うためとか、ニッチになった感がありました。CPUのシングルスレッド性の向上が見込めなくなった昨今、アセンブラでのプログラミングが見直されるかもしれません。
話を戻すと、コラッツ予想の確認プログラムの場合、スレッド数を100にしても性能が伸びていることを確認できます。これは、前述のとおり値により処理ステップにばらつきがあるためで、区間を細かくした方が(スレッド数を多くし多方が)、CPUから見た場合のトータル処理時間が平均化される為です。
Intel Turbo Boost Max Technology 3.0 と ハイパバイザー
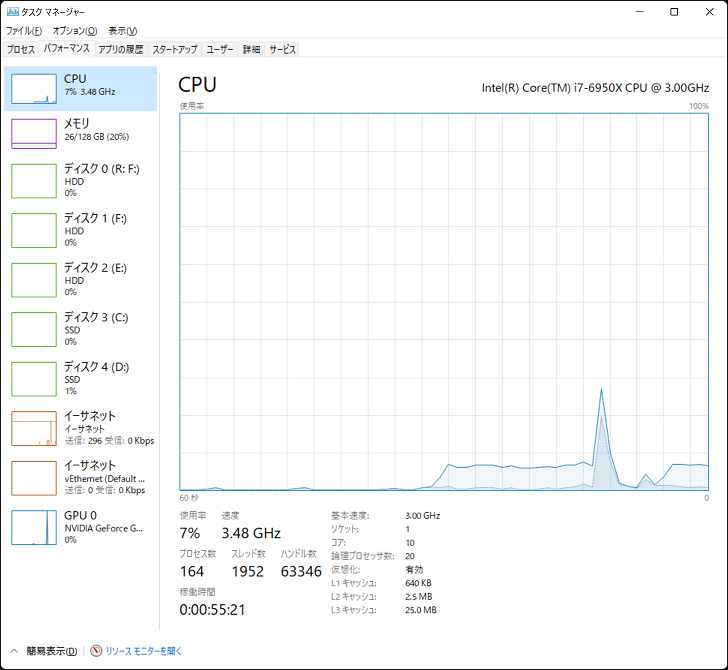
Intel Turbo Boost Max Technology 3.0(ITBM)とは、Broadwell-E以降のハイエンドCPUに搭載された機能で、要するに「さらにブーストする(クロック周波数が上がる)」機能になっている。Core i7-6950X(Broadwell-E)の場合、従来のブースト(Intel Turbo Boost Technology 2.0)では、3.5GHzまでの最大周波数となるが、3.0になると、1コアのみであるが4.0GHzまでブーストする。下記タスクマネージャの画面では3.88GHzまで周波数が上がっている。
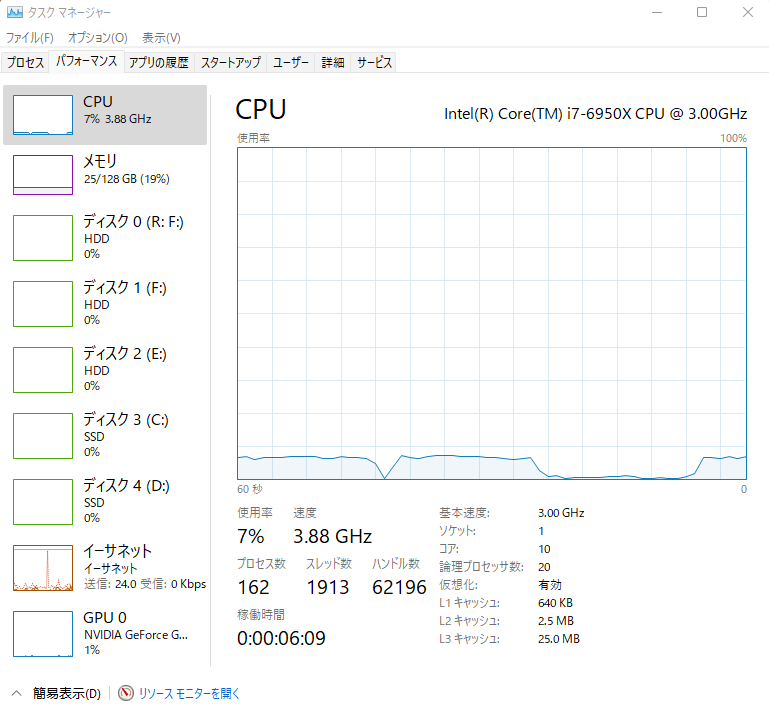
比較で、下記はIntel Turbo Boost Technology 2.0までが有効のちょうど1世代前のCore i7-5960X(Haswell-E)のタスクマネージャの画面。3.47GHzまで周波数が上がっている。
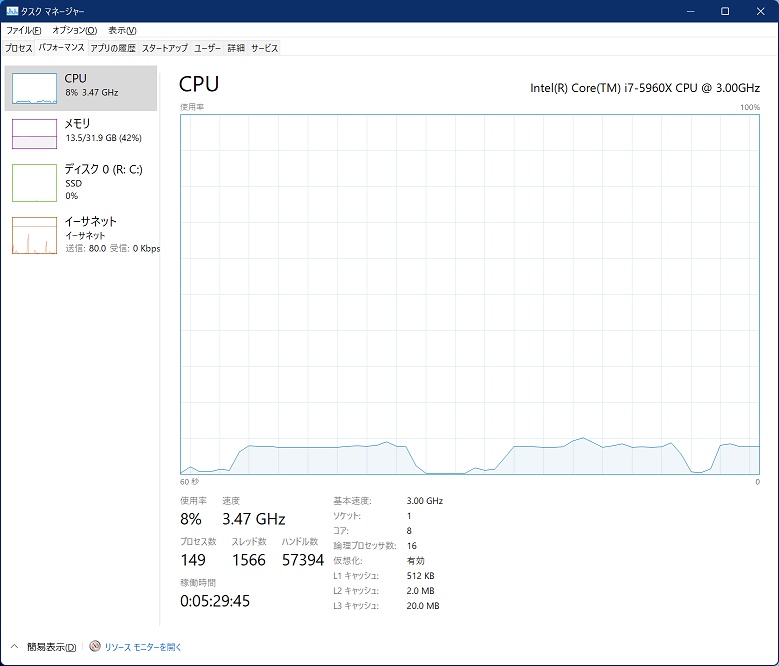
以前、Core i7-6950Xを入手しましたが、Windows11のセットアップを行い、Intel Turbo Boost Max Technology 3.0(ITBM)のドライバーを入れたが、気が付いたらログイン時に起動時にエラーが出るようになった。
「ITBM Driver Not Available
Exiting application」
これは、Intel Turbo Boost Max Technology 3.0のコンソール画面の起動時にでていて、結局コンソール画面は出てこなくなった。
クロック周波数を見てみると、下記のように5960Xレベル(Intel Turbo Boost Technology 2.0)まで周波数が落ちていることが解る。
エラーメッセージで調査をしたのですがエラーメッセージの検索では不具合原因にはたどりつかなかった。長らくそのまま放置していたが、最近分かったのが、どうもハイパバイザーをONにしているとダメらしいことが解った。さらに調査をしていくと、
インテルのサポートページ(ページを見るには登録が必要)を見るとTurbo Boost Max Technology 3.0はサポートしているが、Intel® Turbo Boost Max driver solutionはサポートしていないという一見、良くわからん回答があった。
どうやら、driverは動かないということなので、「ITBM Driver Not Available」との整合性がとれる。
結局、Turbo Boost Max Technology 3.0は動作しないのか?という話になるが、Turbo Boost Max Technology 3.0は以下の2つの機能がある。
(1)全コアに負荷がかかってもブーストクロックまでブーストする
(2)1コアだけ、より高クロックにブーストする。
で、どうやらハイパバイザー環境では(1)は有効となるが、(2)が無効になるらしい
ということで、試しにCinebenchで全コアに負荷をかけてみたが、確かに約3.5GHzまで動作した。ちなみにCore i7-5960Xの場合、全コアに負荷をかけると3.3GHzまで周波数が落ちた。
6950Xと5960Xを比べると、ハイパバイザーを使うならコア数が多くさらに最大メモリ搭載量が倍の6950Xが良いが、Turbo Boost Max Technology 3.0の機能に制限が加わるのは痛い。悩ましいところである。
追記:
Vtuneを使おうとするとハイパバイザーを止めなければならず、結局、6950Xのマシンと5960Xのマシンのメモリを入れ替えて5960Xの方をハイパバイザーを使うように変えた。
[ADP開発日誌]Ver 0.82のリリース
忙しさにかまけてブログの更新を怠っていましたが、気がつけば今月末でADP公開2周年になります。公開一周年記念の記事も完成していないのに、時の立つのは速いものだと感慨に浸っております。というわけで、間が空きましたがVer 0.82のリリースです。
今回の変更点は、
・バグフィックス
・sprintfの改修
・パフォーマンスの改善
になります。
また、今回のリリースからホスティングサイトをSourceforge.JpからSourceforge.netに変えました。
sprintfの改修ですが、詳しくはsprintfのマニュアルをご参照頂くとして、たとえばDBからの戻り値をsprintfで成型する場合に、便利に使えるようにしています。
例えば、以下のように記述することができます。
,db.sql@("SELECT * FROM users WHERE hogehoge ",[]).each.
sprintf("%s:first_name; %s:secondname;様 の誕生日は、%s:birth_dayです。").
prtn,next;
DBの取得から成型、表示まで一気に書けるところがAnother Data Processorらしくなかなかよろしいかと思います(自画自賛)。
パフォーマンスの改善ですが、Ver 0.60以来の改善になります。
Ver 0.60から0.81になったことでパフォーマンスが下がりましたが、Ver 0.82は0.60以上のパフォーマンスになりました。
前回と環境が変わりましたので改めてベンチマークをとりますと、
◆Windows上でのJavaScript vs ADP
■マシン
・CPU Core i7-920(2.66GHz HT/Turbo Boost OFF)
・メモリ 12GB(DDR3-1066 2GB × 6)
・OS Windows 7 Ulitimate (x64) 電源管理:高パフォーマンス
■結果
| IE8(64ビット版) | 452ミリ秒 |
| FireFox 13.0.1 | 12ミリ秒 |
| ADP 0.60(32ビット) | 343ミリ秒 |
| ADP 0.81(32ビット) | 452ミリ秒 |
| ADP 0.82(32ビット) | 265ミリ秒 |
0.60と比べても20%以上速くなっています。今回はChromeの結果を掲載していません。またFireFoxですが、12ミリ秒とかなり速いです。前回パフォーマンスについて『FireFox3.6未満』と記載しましたが、残念ならがFireFoxと比較するのは厳しくなりました。
という訳で別の比較が必要になりましたので、ADPと、PHP、Javaと比べてみます。
◆CentOS6.2上でのPHP,Java,ADP
■マシン
・CPU Core i7-980X(3.33GHz HT/Turbo Boost OFF)
・メモリ 24GB(DDR3-1066 4GB × 6)
・ホストOS Windows 2008R2(Hyper-V)
・ゲストOS CentOS 6.2(実行環境)
■テストコード
テスト1:28のフィボナッチ数を求める PHPソース(Test1.php) Javaソース(Test1.java) ADPソース(Test1.p)
テスト2:10万までの素数を求める PHPソース(Test2.php) Javaソース(Test2.java) ADPソース(Test2.p)
テスト2のPHPのコードですが、Stackoverflowさんのコードを使わせて頂きました。
■結果(timeコマンドのuser部分を抜き出した)
| テスト1 | テスト2 | |
|---|---|---|
| PHP(5.3.3) | 207ミリ秒 | 31,915ミリ秒 |
| Java(1.6) | 38ミリ秒 | 4,862ミリ秒 |
| ADP(0.82) | 190ミリ秒 | 3,765ミリ秒 |
テスト結果をみますとADPはPHP5.3以上のパフォーマンスが出ています。特にテスト2の結果が1桁近く速くなっており、Javaよりも早くなっています。テスト1ではADPよりJavaが圧倒的に速いのですが、テスト2ではADPの方が速くなっています。テスト2のJavaはコレクションクラス(ArrayList)を使っておりその分遅くなっているようです。実際にこの部分を固定配列にすると実行速度は1/10になります(もっともコレクションクラスを使わないという選択肢はないかとも思いますが)。ADPの配列はC++で実装しています。私自身気づいていませんでしたが、かなり効率良く実装されているようです。
また、テスト2の、リンク先のトピックは元々「PythonがPHPより遅いのだが?」という質問でしたがADPのパフォーマンスはそれ以上なのでいわゆるスクリプト言語より速いことが解ります。
もっとも一部のテストからですので今後も色々ベンチマークテストを行い検証しようかと思います。
ちなみに、もっと大幅にパフォーマンスアップが望める改善策を思いついたのですが、かなりの改修が必要なので、ここまでの成果を0.82としてリリースし、より速くしたものを後のバージョンで出そうかと思っています。打倒JavaScriptですね(まぁJITを入れないとダメなような気がするが・・・)。
JOINのパフォーマンスについての考察2(リレーションとの関係2)
ちょっと間があきましたが、JOINのパフォーマンス関連の続きになります。
前回、JOINのパフォーマンスについての考察(リレーションとの関係)でJOINを行った結果、データが非正規化するとその非正規化の度合いによってパフォーマンスが下がるという話をしました。
前回の記事では、1対nの結合ではJOINを外す(単純なSQLに分割してホスト言語側で結合させる)ということで、定性的な話しかしていませんでしたが、幾つか実験を通して、もう少し定量的な話をしてみます。
『たかがJOINで、なぜこねくり回すのか?』と思われるかもしれませんが、こういう実験&考察というのは意外に行われていないかと思います。私自身定性的なことは理解していたつもりでしたが、実際に実験を行うと色々と発見がありますので、記事にしてみます。
大切なことは解った気になることではなく真実を追究する姿勢で、先入観を持たずにきちんと実験を行いパフォーマンスに対する感性をみがくことは大切かと思います。
今回、調査するアルゴリズムについて
今まで何回か実験してきましたが、実験で使用してきたアルゴリズムについて説明します。1.SQLでJOINを行う。
SELECT Price.CODE, RDATE, OPEN, CLOSE, NAME FROM Price INNER JOIN Company ON (Price.CODE = Company.CODE)という風にSQLでJOINを行います。普通の処理になります。
2.ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,RDATE,OPEN,CLOSE FROM Price (2) SELECT NAME FROM Company WHERE CODE = ?
(1)のSQLを実行して結果を取得しますが、NAMEについては(2)のように再度SQLを発行します。
ここで、単純にPriceテーブルの全ての行に対して(2)SQLを発行するのではなく同じ結果をキャッシュして同じCODEの場合はキャッシュからデータを取得するようにします。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
1.のSQLを以下のように分割します。(1) SELECT CODE,NAME FROM Company (2) SELECT CODE,RDATE,OPEN,CLOSE FROM Price
(2)のPriceテーブルからのデータの取得に先立ちまして、(1)でComapnyテーブルから全てのデータを取得しておきます。
多くのDBMSで行っているハッシュ結合を真似ています。
1対nの2つのテーブルのJOINにおけるパフォーマンスモデル式
続いて、各アルゴリズムのパフォーマンス(実行時間)のモデル式を示します。ここで、
n : Priceテーブルの行数
m : Companyテーブルの行数
c10,c10,c20,c21,c22,c23,c30,c31,c32 : 比例定数
になります。
1.SQLでJOINを行う
1.のパフォーマンスのモデル式は以下のようになります。c11 * n + c10
Priceテーブルの行数に比例した時間で結果を取得できます。ここでc11は比例定数であり、C10はオーバーヘッドにあたります。
2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)
2.のパフォーマンスのモデル式は以下のようになります。c21 * n + c22 * m + c20
Priceテーブルの行数に比例した時間と、Companyテーブルの行数に比例した時間およびオーバーヘッドの合計になります。
『c22 * m は c22 * n * m になるのでは?』と思われるかと思いますが、キャッシュのおかげでこのようになります。
また、「1.SQLでJOINを行う」と比べますと、c22 * m と余計な項が付いていますので、
SQLでJOINした方が速い
と早合点される方がいらっしゃるかと思いますが、JOINのパフォーマンスについての考察(リレーションとの関係)で述べたことは、c11とc22の定数値の差異となって現れてきます。
3.ホスト言語側でJOINを行う(ハッシュJOINを行う)
3.のパフォーマンスのモデル式は以下のようになります。c31 * n + c32 * m + c30
面白いことですが、形式的には「2. ホスト言語側でJOINを行う(キャッシュ付のネステッドループJOINを行う)」と同じになります。
ちなみに、[ADP開発日誌]SQL(JOIN)の実行パフォーマンスについて2011 にあります、「SQLの発行回数のオーバヘッドはどこにいったんや?」と思われるかもしれませんが、それはc32とc22の差異に出てくるということになります。
実験と結果
今回の実験では、nの値を変えながら実行時間を計測することにより、各モデル式の定数を求めます。求めるといってもグラフを書いて状況を観測します。厳密には回帰分析とかを行うことになるでしょうが、グラフが直線になることと、nが増えたときの傾向をつかめればよろしいかと思います。アルゴリズムの教科書ではオーダーという概念があり、オーダーでは定数を求めることは無意味とされています。つまり上記のアルゴリズムは論理的には違いがなくどれも一緒ということになります。
つまり、2倍や3倍の差はあまり意味がないということですが、もっとも、実際の現場ではこのような差にも敏感になるので、きちんと計測して値を出すことになります。
また、今回はmは固定(約2000)で行っています。mが変動したときにどう変わるのかも興味深いですが今回は、m << n ということで結果にはあまり影響しません。
先ずは、結果から、
| 0行 | 373,740行 | 1,172,191行 | 2,002,749行 | 4,671,568行 | |
|---|---|---|---|---|---|
| 1.SQLでJOIN | 718 | 10,015 | 29,938 | 52,329 | 119,192 |
| 2.キャッシュ付のネステッドループJOINを行う | 671 | 10,469 | 30,172 | 49,814 | 116,770 |
| 3.ハッシュJOINを行う | 2,828 | 11,422 | 29,797 | 49,845 | 110,988 |
つづいて、グラフを以下に示します。
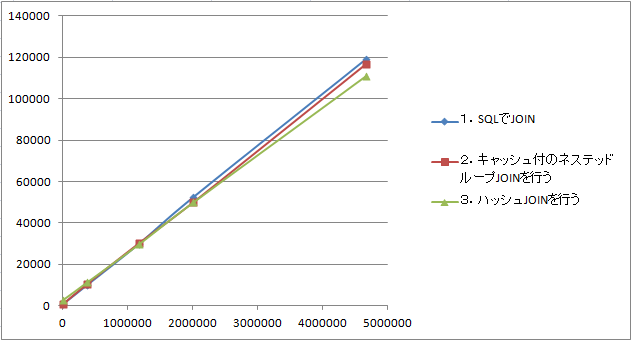
縦軸が時間で、横軸が行数(n)になります。グラフをみますとPriceテーブルの行数(n)が増えると「1.SQLでJOIN」より、「2.キャッシュ付のネステッドループJOINを行う」や「3.ハッシュJOINを行う」の方が速くなっていくことが解るかと思います。
パフォーマンスにシビアになる時は、往々にしてnの行数が増えるような場合にあたるということになります。その場合は1より2や3を選択した方がよいということになります。
もっともグラフを見て解るとおり差はあまりないので、通常はやはり普通にSQLでJOINを行い、パフォーマンスを稼ぎたくなったら2や3を検討するということになるでしょう。